Original Link: https://www.anandtech.com/show/16195/a-broadwell-retrospective-review-in-2020-is-edram-still-worth-it
A Broadwell Retrospective Review in 2020: Is eDRAM Still Worth It?
by Dr. Ian Cutress on November 2, 2020 11:00 AM EST
Intel’s first foray into 14nm was with its Broadwell product portfolio. It launched into the mobile market with a variety of products, however the desktop offering in 2015 was extremely limited - only two socketed desktop processors ever made it to retail, and in limited quantities. This is despite users waiting for a strong 14nm update to Haswell, but also because of the way Intel built the chip. Alongside the processor was 128 MB of eDRAM, a sort of additional cache between the CPU and the main memory. It caused quite a stir, and we’re retesting the hardware in 2020 to see if the concept of eDRAM is still worth the effort.
eDRAM: The Savior
In recent years, Intel has pushed hard its infamous ‘Pyramid of Optane’, designed to showcase the tradeoff between small amounts of cache memory close to the CPU being low latency, out to the large offline storage offered for at a significant ping time. When a processor requires data and instructions, it navigates this hierarchy, with the goal to have as much of what is required as close to the CPU (and therefore as fast) as possible.
Traditional modern x86 processors contain three levels of caches, each growing in size and latency, before reaching main memory, and then out to storage. What eDRAM does is add a fourth layer between the last L3 cache on the processor. Whereas the L3 is measured in single digit megabytes, the eDRAM is in the 10s-100s of megabytes, and DRAM measures in gigabytes. Whereas the L3 cache is located on the processor die and low latency, the eDRAM is slightly higher latency, and the main memory is on modules outside the processor socket at the highest latency. Intel enabled an ‘eDRAM’ layer as a separate piece of silicon with the processor package, up to 128 MiB, offering latency and bandwidth between the L3 and main memory.
This piece of silicon was built on Intel’s 22nm IO manufacturing process, rather than 22nm SoC or 14nm, due to Intel’s ability to drive higher 22nm frequencies at the time.

By keeping the eDRAM as a separate piece of silicon, it allowed Intel to adjust stock levels based on demand – if the product failed, there would still be plenty of smaller CPU die for packaging. Even today, processors made with extra eDRAM use the same die as seen back in 2013-2015, showing the longevity of the product. The first eDRAM products were mobile under the 22nm Haswell microarchitecture, but Broadwell saw it come to desktop.
On the Broadwell processors, this resulted in a memory access layer with the following performance:
| Broadwell Cache Structure | ||||
| AnandTech | Size | Type | Latency | Bandwidth |
| L1 Cache | 32 KiB / core | Private | 4-cycle | 880 GiB/s |
| L2 Cache | 256 KiB / core | Private | 12-cycle | 350 GiB/s |
| L3 Cache | 6 MiB | Shared | 26-50 cycle | 175 GiB/s |
| eDRAM | 128 MiB | Shared | < 150 cycle | 50 GiB/s |
| DDR3-1600 | Up to 16 GiB | Shared | 200+ cycle | 25.6 GiB/s |
The simplistic view of this eDRAM was as a ‘level 4’ cache layer – this is ultimately how it was described to us at the time, with the eDRAM layer acting as a victim cache accepting L3 evictions but enabled through a shadow tag system accessed through the L3. Data needed from the eDRAM would have to be moved back into L3 before going anywhere else, including the graphics or the other IO or main memory. In order to do this, these shadow tags required approximately 0.5 MiB/core of the L3 cache, reducing the L3 usefulness in exchange for lower latency extending out to 128 MiB. This is why Broadwell only had 1.5 MiB/core of L3 cache, rather than the full 2.0 MiB/core that the die shot suggested it should have.
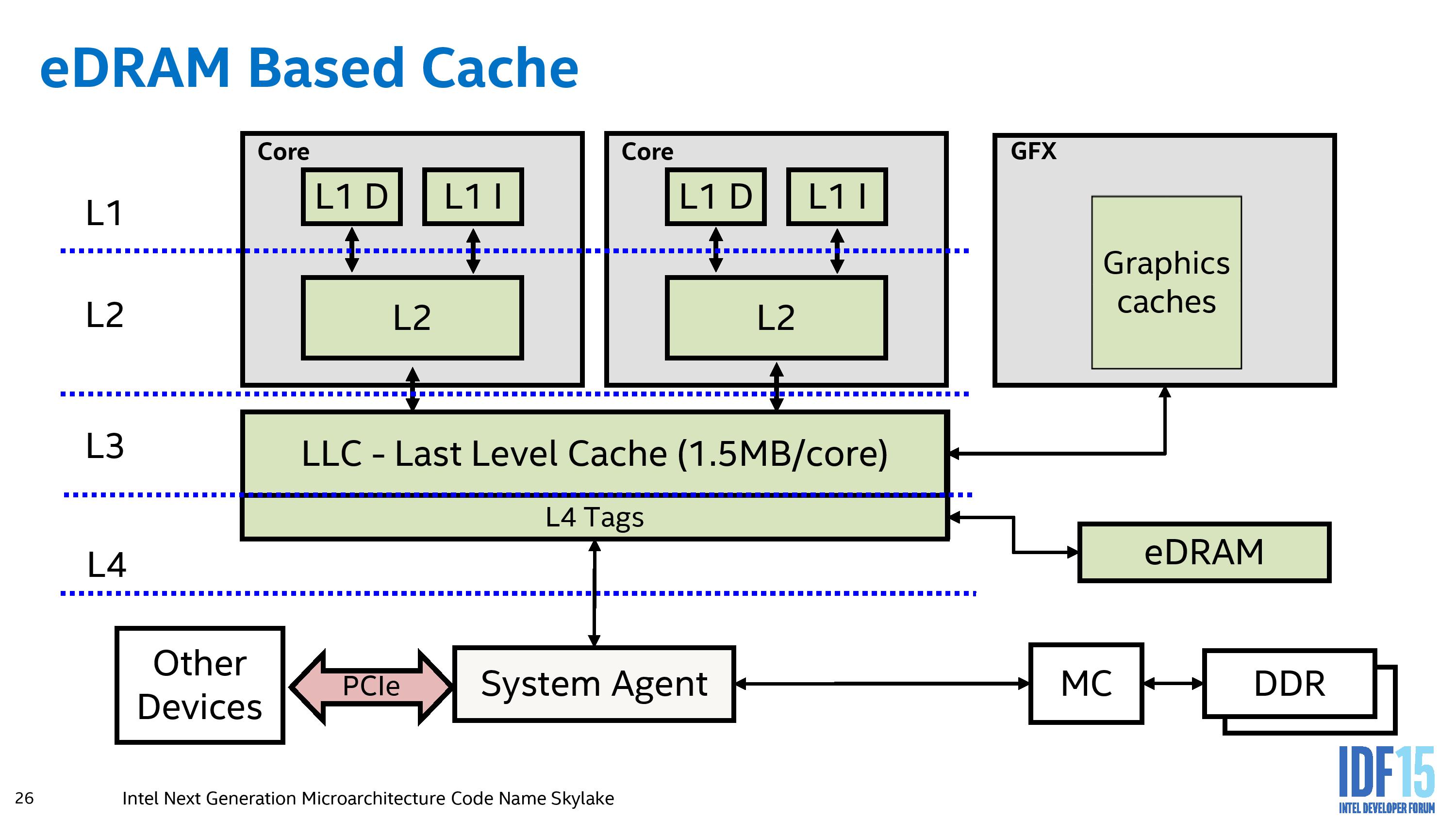
Haswell/Broadwell eDRAM Layout
The eDRAM could be dynamically split on the fly for CPU or GPU requests, allowing it to be used in CPU-only mode when the integrated graphics are not in use, or full for the GPU when texture caching is required. The interface was described to us at the time as a narrow double-pumped serial interface capable of 50 GiB/s bi-directional bandwidth (100 GiB/s aggregate), running at a peak 1.6 GHz.
In this configuration, in combination with the graphics drivers, allowed for more granular control of the eDRAM, suggesting that the system could pull from both the eDRAM and the DDR memory simultaneously, potentially giving a peak memory bandwidth of 75.6 GiB/s, at a time when mid-range graphics cards such as the GT650M had a bandwidth around 80 GiB/s.
The second generation of the eDRAM design, as found in Skylake and future processors, moved the eDRAM out of the purview of the L3 cache, and enabled it as a purely transparent buffer between the system agent and the main DRAM memory controller, making it invisible to CPU/GPU accesses or IO accesses. This allows the cache to be accessed by all DRAM requests, enabling full coherency (although the drivers still allow it to be bypassed for textures larger than the eDRAM size), as well as removing the 0.5 MiB/core L3 cache reduction for shadow tags.
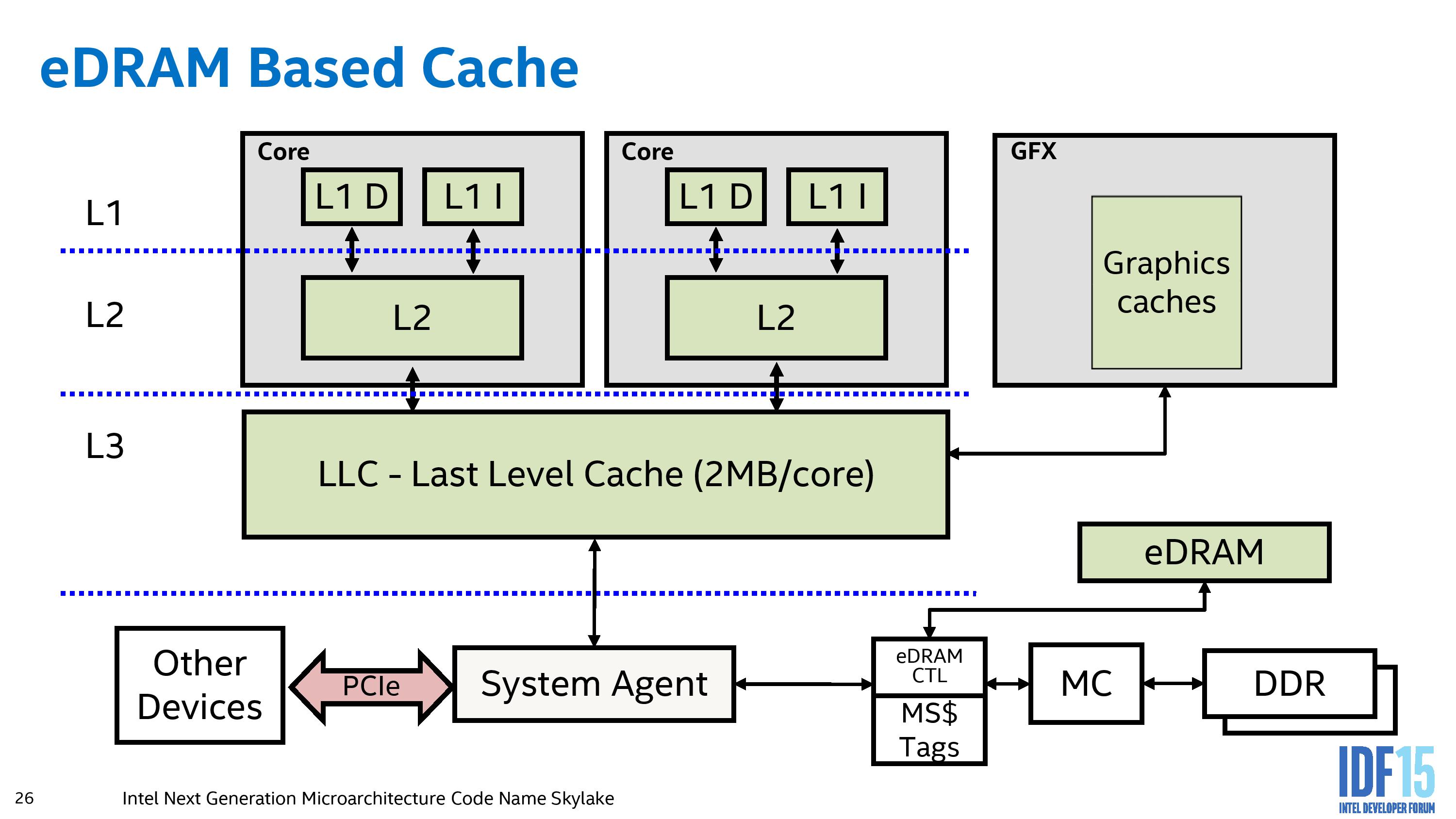
Skylake-and-beyond eDRAM Layout
There are arguments to be made about whether the eDRAM as an L4 victim cache or as a transparent buffer to DRAM is the correct direction to go – as a victim cache, Intel stated it allowed a cache hit rate over 95%, however in a number of scenarios in order to get the best performance it required software intervention, and a lot of software was not aware of such a configuration. As a buffer, it enabled seamless integration that all software can take advantage of, but it is not necessarily as optimizable as an L4 victim cache.
‘Go Big or Go Home’
For Broadwell’s eDRAM products, Intel enabled a 128 MiB implementation, quadruple that found on Xbox One silicon at the time. At the time, Intel said that a 32 MiB eDRAM L4 victim cache enabled substantial hit rates, but the company wanted the design to be futureproof as well as a long-term option in Intel’s product stack, so it was doubled, and doubled again just to be sure. The term was ‘go big or go home’, and in our initial review of the first Broadwell eDRAM products, Anand noted that it was very rare to see Intel be so ‘liberal’ with die area.
The eDRAM silicon was built on the 22nm SoC process, as mentioned, one node behind Intel’s leading edge CPU designs. The 128 MiB design came in at a die size of ~77 mm2, contributing to over a third of the total die area used in the 14nm Broadwell Iris Pro quad-core processor package (182mm2 + 77mm2 = 259 mm2).
In the subsequent next generation Skylake generation, eDRAM models with 64 MiB were also offered.
Under certain constraints, the system could save power by disabling the main memory controller entirely if all the data required over a period of time is available in the eDRAM. As part of the initial Broadwell launch, Intel described the extra power consumption of the eDRAM as under 1 watt at idle, moving up to a peak of 5 watts when operating at full bandwidth. Ultimately this means that at a chip level, less power is available to the cores should it be needed, but the trade-off will be better performance in memory limited scenarios. The power is meant to be tracked by the on-die PCU, or Power Control Unit, that can shift power budget between the CPU, GPU, eDRAM, as needed by performance counters or thermals.
As part of this review, we are able to give at least some insights into this number. In our testing, we saw idle package power numbers for the following processors:
- Core i7-4790S (22nm Haswell 4 core 6 MiB L3): 6.01 W
- Core i7-5775C (14nm Broadwell 4 core 6 MiB L3 + 128 MiB eDRAM) 9.71 W
- Core i7-6700K (14nm Skylake 4 core 8 MiB L3): 6.46 W
These numbers would suggest that the effect of the eDRAM, at idle, is more akin to 3.3-3.7 watts, not the sub 1-watt that Intel suggested. Perhaps that sub 1-watt value was more for mobile processors? When running at a steady-state full load, the processors reported power values of their TDP, which doesn’t enable any insight.
Broadwell’s eDRAM Flop?
Intel had somewhat backed itself into a corner with its Broadwell launch. Due to the delays of Intel’s 14nm process at the time, the company had decided to follow its popular Haswell-based 22nm Core i7-4770K high-end processor with the launch of a higher binned ‘Devil’s Canyon’ processor, the Core i7-4790K. This processor offered +500 MHz, which at the time was a substantial jump in performance, despite the processors being launched 12 months apart.
Devil’s Canyon Review: Intel Core i7-4790K and i5-4690K
Because Broadwell ‘wasn’t ready’, Devil’s Canyon was designed to be a stop-gap measure to appease Intel’s ever-hungry consumers and high-end enthusiasts. From the consumer point of view, Devil’s Canyon was at least a plus, but it gave Intel a significant headache.
By bumping the clock speed of its leading consumer processor by a significant margin, Intel now had a hill to climb – the goal of a new product generation is that it should be better than what came before. By boosting its previous best to be even better, it meant the next generation had to do even more. This is difficult to do when the upcoming process node isn’t working quite right. This meant that in the land of the desktop processor, Intel’s reluctance to launch Broadwell with eDRAM was painful to see, and the company had to change strategy.

Intel almost made Broadwell for desktops a silent launch, with very little fanfare. After the announcement, there was almost zero stock on shelves. At the time, Intel did not sample the processors for review – we were able to obtain units from other sources a few days in advance for our launch day coverage.
The Intel Broadwell Desktop Review: Core i7-5775C and Core i5-5675C Tested (Part 1)
The Intel Broadwell Review Part 2: Overclocking, IPC and Generational Analysis
By launching Broadwell Core i7 as a 65 W processor rather than an 84-88 W processor, it meant that the lower frequency Broadwell wasn’t necessarily a direct comparison to Devil’s Canyon. It came out of the gate with a frequency deficit, however the presence of the eDRAM would enable some very careful wins in memory limited scenarios, and perhaps most importantly, gaming.
Ultimately the stunted launch of desktop Broadwell in June 2nd 2015 was very quickly followed by launch of Skylake on August 5th 2015, and the top Core i7 processor was once again an 88+ watt unit and a true like-for-like competitor to Devil’s Canyon. Skylake also enabled DDR4 in the market, which was a significant upgrade on the memory front.
Unfortunately Intel had another conundrum – the older Broadwell processors, due to the eDRAM, actually offered slightly better gaming performance than Skylake! It was title, resolution, and quality dependent, and some might argue there was only a few percentage points in it, but for those that wanted the best at gaming, Skylake wasn’t necessarily the answer. For pretty much all CPU tasks though, Skylake was the answer.
Broadwell Still Available Today
Ultimately, Intel’s foray into socketed Broadwell processors with eDRAM was a momentary blip in its line of consumer-focused Core products. At the time, the processors were hard to find for sale, and were quickly made old by the arrival of Skylake and DDR4. There were six different Broadwell processors that were socketable, two mainstream Core products and four Xeon E3 parts.

| Intel Broadwell eDRAM Socketable CPUs | ||||||
| AnandTech | Cores Threads |
Base Freq |
Turbo Freq |
IGP | IGP Freq |
TDP |
| Consumer Core | ||||||
| i7-5775C | 4C / 8T | 3300 | 3700 | 48 EUs | 1150 | 65 W |
| i5-5675C * | 4C / 4T | 3100 | 3600 | 48 EUs | 1100 | 65 W |
| * Sometimes listed as Core i7-5675C as some ES had an incorrect CPUID string | ||||||
| Enterprise Xeon E3 v4 | ||||||
| E5-1285 v4 | 4C / 8T | 3500 | 3800 | 48 EUs | 1150 | 95 W |
| E5-1285L v4 | 4C / 8T | 3400 | 3800 | 48 EUs | 1150 | 65 W |
| E3-1270L v4 | 4C / 8T | 3000 | 3600 | - | - | 45 W |
| E3-1265L v4 | 4C / 8T | 2300 | 3300 | 48 EUs | 1050 | 35 W |
We were able to also review three of the Xeons at the time.
The Intel Broadwell Xeon E3 v4 Review: 95W, 65W and 35W with eDRAM
Most of these processors are actually very easy to purchase today. The best place to find them are either on Aliexpress, or eBay, for as little as $104.
Broadwell in 2020
The main highlight of these processors was the high-speed eDRAM, coming up to 50 GiB/s bidirectional, at a time when the DDR3-1600 memory solution in dual channel could only offer 25.6 GiB/s. At some point in the future, it would be expected for the speed of normal DRAM to surpass this bandwidth offered, even if it can’t exactly match that latency.
We actually reached that mark very recently.
- Intel’s best consumer-grade processor is the Intel Core i9-10900K, offering 10 cores up to a peak 5.3 GHz, but most importantly the memory side has official support for DDR4-2933, which in dual channel mode would enable 46.9 GiB/s.
- Current AMD Zen 2 processors have a peak supported frequency of DDR4-3200, which in dual channel mode would enable 51.2 GiB/s bandwidth.
- Intel’s mobile Tiger Lake processors support LPDDR4X-4266, which when fully populated would provide 68.2 GiB/s bandwidth.
- With the introduction of DDR5 set to come in the next couple of years, we are expecting to see DDR5-4800 as a possible entry point. This would enable 38.4 GiB/s per 64-bit channel, or 76.8 GiB/s in a standard consumer configuration.
Perhaps it is difficult to wrap your head around the fact that only in 2020 are we matching bandwidth levels that were enabled back in 2015 by the addition of a simple piece of silicon. It might make you question why Broadwell was the only family of Intel’s socketable processors to get this innovation – all future eDRAM products were all for mobile devices that rely on integrated graphics, despite the benefits observed for discrete graphics configurations.

It should be noted that because eDRAM offers a latency benefit in memory accesses from 6 MiB to 128 MiB, then as we approach the situation where a single core has access to 128 MiB of L3 cache, this benefit would also disappear. For consumer processors, we’re not there quite yet – while Intel processors offer up to 20 MiB (or 24 MiB in upcoming Tiger Lake 8-core processors), AMD’s future Zen 3 processors will offer access to 32 MiB of L3 for each core within a CCX. By that metric, we’re still very far behind.
For this review, because we recently tested Intel’s Tiger Lake quad-core processors and graphics, I wanted to probe exactly where Broadwell will finally sit in the hierarchy of CPU performance and graphics performance. We recently announced a new benchmark and gaming suite, and Broadwell is always one of the interesting products to put on a new test suite.
All integrated gaming tests (as well as gaming tests with an RTX 2080 Ti) will be under the respective game pages.
Pages In This Review
- Analysis and Competition
- Test Setup and #CPUOverload Benchmarks
- Power Consumption
- CPU Tests: Office and Science
- CPU Tests: Simulation
- CPU Tests: Rendering
- CPU Tests: Encoding
- CPU Tests: Legacy and Web Tests
- CPU Tests: Synthetics
- CPU Tests: SPEC
- CPU Tests: Microbenchmarks
- Gaming: Chernobylite
- Gaming: Civilization VI
- Gaming: Deus Ex: MD
- Gaming: Final Fantasy XIV
- Gaming: Final Fantasy XV
- Gaming: World of Tanks
- Gaming: Borderlands 3
- Gaming: F1 2019
- Gaming: Far Cry 5
- Gaming: Gears Tactics
- Gaming: GTA 5
- Gaming: Red Dead Redemption 2
- Gaming: Strange Brigade
- Conclusions and Final Words
Test Setup
As per our processor testing policy, we take a premium category motherboard suitable for the socket, and equip the system with a suitable amount of memory running at the manufacturer's maximum supported frequency. This is also typically run at JEDEC subtimings where possible. It is noted that some users are not keen on this policy, stating that sometimes the maximum supported frequency is quite low, or faster memory is available at a similar price, or that the JEDEC speeds can be prohibitive for performance. While these comments make sense, ultimately very few users apply memory profiles (either XMP or other) as they require interaction with the BIOS, and most users will fall back on JEDEC supported speeds - this includes home users as well as industry who might want to shave off a cent or two from the cost or stay within the margins set by the manufacturer. Where possible, we will extend out testing to include faster memory modules either at the same time as the review or a later date.
| AnandTech | Example Processors |
Motherboard | DRAM | PSU | SSD |
| Intel | |||||
| Haswell | Core i7-4790K | GIGABYTE Z97X-UD5H (F10) |
Geil Veloce 16 GB DDR3-1600 |
Antec HCP 1250W |
Crucial MX500 2 TB |
| Core i7-4790S | |||||
| Broadwell | Core i7-5775C | GIGABYTE Z97X-UD5H (F10) |
Geil Veloce 16 GB DDR3-1600 |
Antec HCP 1250W |
Crucial MX500 2 TB |
| Core i5-5675C | |||||
| Skylake | Core i7-6700K | GIGABYTE X170-Extreme ECC (F21e) |
G.Skill Ripjaws 32 GB DDR4-2133 |
Corsair AX860i |
Crucial MX300 1 TB |
| Core i5-6600K | |||||
| Comet Lake | Core i7-10700 | ASRock Z490 PG Velocita (P1.50) |
Corsair RGB Dominator Pro 32 GB DDR4-2933 |
Corsair AX860i |
Crucial MX500 2 TB |
| Core i5-10600K | |||||
| Tiger Lake | Core i7-1185G7 | Intel Reference |
32 GB LPDDR4X |
Integrated | Samsung PCIe 3.0 |
| AMD | |||||
| Zen+ APU | Ryzen 5 3400G | GIGABYTE X570 Aorus I Pro (F30a) |
ADATA 32 GB DDR4-3200 |
Corsair AX860i |
Crucial MX500 2 TB |
| Athlon 300GE | |||||
| Zen2 APU | Ryzen 5 4650G | GIGABYTE X570 Aorus I Pro (F30a) |
ADATA 32 GB DDR4-3200 |
Corsair AX860i |
Crucial MX500 2 TB |
| Ryzen 3 4350G | |||||
| Zen2 CPU | Ryzen 7 3700X | GIGABYTE X570 Aorus I Pro (F30a) |
ADATA 32 GB DDR3-3200 |
Corsair AX860i |
Crucial MX500 2 TB |
| Ryzen 5 3600 | |||||
Many thanks to...
We must thank the following companies for kindly providing hardware for our multiple test beds. Some of this hardware is not in this test bed specifically, but is used in other testing.
| Hardware Providers for CPU and Motherboard Reviews | |||
| Sapphire RX 460 Nitro |
NVIDIA RTX 2080 Ti |
Crucial SSDs | Corsair PSUs |
 |
|
 |
 |
| G.Skill DDR4 | ADATA DDR4 | Silverstone Coolers |
Noctua Coolers |
 |
|
 |
 |


A big thanks to ADATA for the AD4U3200716G22-SGN modules for this review. They're currently the backbone of our AMD testing.
The 2020 #CPUOverload Suite
Our CPU tests go through a number of main areas. We cover Web tests using our un-updateable version of Chromium, opening tricky PDFs, emulation, brain simulation, AI, 2D image to 3D model conversion, rendering (ray tracing, modeling), encoding (compression, AES, video and HEVC), office based tests, and our legacy tests (throwbacks from another generation of code but interesting to compare).
The Win10 Pro operating system is prepared in advance, and we run a number of registry edit commands again to ensure that various system features are turned off and disabled at the start of the benchmark suite. This includes disabling Cortana, disabling the GameDVR functionality, disabling Windows Error Reporting, disabling Windows Defender as much as possible again, disabling updates, and re-implementing power options and removing OneDrive, in-case it sprouted wings again.
A number of these tests have been requested by our readers, and we’ve split our tests into a few more categories than normal as our readers have been requesting specific focal tests for their workloads. A recent run on a Core i5-10600K, just for the CPU tests alone, took around 20 hours to complete.
Power
- Peak Power (y-Cruncher using latest AVX)
- Per-Core Loading Power using POV-Ray
Office
- Agisoft Photoscan 1.3: 2D to 3D Conversion
- Application Loading Time: GIMP 2.10.18 from a fresh install
- Compile Testing (WIP)
Science
- 3D Particle Movement v2.1 (Non-AVX + AVX2/AVX512)
- y-Cruncher 0.78.9506 (Optimized Binary Splitting Compute for mathematical constants)
- NAMD 2.13: Nanoscale Molecular Dynamics on ApoA1 protein
- AI Benchmark 0.1.2 using TensorFlow (unoptimized for Windows)
Simulation
- Digicortex 1.35: Brain stimulation simulation
- Dwarf Fortress 0.44.12: Fantasy world creation and time passage
- Dolphin 5.0: Ray Tracing rendering test for Wii emulator
Rendering
- Blender 2.83 LTS: Popular rendering program, using PartyTug frame render
- Corona 1.3: Ray Tracing Benchmark
- Crysis CPU-Only: Can it run Crysis? What, on just the CPU at 1080p? Sure
- POV-Ray 3.7.1: Another Ray Tracing Test
- V-Ray: Another popular renderer
- CineBench R20: Cinema4D Rendering engine
Encoding
- Handbrake 1.32: Popular Transcoding tool
- 7-Zip: Open source compression software
- AES Encoding: Instruction accelerated encoding
- WinRAR 5.90: Popular compression tool
Legacy
- CineBench R10
- CineBench R11.5
- CineBench R15
- 3DPM v1: Naïve version of 3DPM v2.1 with no acceleration
- X264 HD3.0: Vintage transcoding benchmark
Web
- Kraken 1.1: Depreciated web test with no successor
- Octane 2.0: More comprehensive test (but also deprecated with no successor)
- Speedometer 2: List-based web-test with different frameworks
Synthetic
- GeekBench 4 and GeekBench 5
- AIDA Memory Bandwidth
- Linux OpenSSL Speed (rsa2048 sign/verify, sha256, md5)
- LinX 0.9.5 LINPACK
SPEC (Estimated)
- SPEC2006 rate-1T
- SPEC2017 rate-1T
- SPEC2017 rate-nT
It should be noted that due to the terms of the SPEC license, because our benchmark results are not vetted directly by the SPEC consortium, we have to label them as ‘estimated’. The benchmark is still run and we get results out, but those results have to have the ‘estimated’ label.
Others
- A full x86 instruction throughput/latency analysis
- Core-to-Core Latency
- Cache-to-DRAM Latency
- Frequency Ramping
- A y-cruncher ‘sprint’ to see how 0.78.9506 scales will increasing digit compute
Some of these tests also have AIDA power wrappers around them in order to provide an insight in the way the power is reported through the test.
2020 CPU Gaming (GPU) Benchmarks
In the past, we’ve tackled the GPU benchmark set in several different ways. We’ve had one GPU to multiple games at one resolution, or multiple GPUs take a few games at one resolution, then as the automation progressed into something better, multiple GPUs take a few games at several resolutions. However, based on feedback, having the best GPU we can get hold of over a dozen games at several resolutions seems to be the best bet.
Normally securing GPUs for this testing is difficult, as we need several identical models for concurrent testing, and very rarely is a GPU manufacturer, or one of its OEM partners, happy to hand me 3-4+ of the latest and greatest. In that aspect, over the years, I have to thank ECS for sending us four GTX 580s in 2012, MSI for sending us three GTX 770 Lightnings in 2014, Sapphire for sending us multiple RX 480s and R9 Fury X cards in 2016, and in our last test suite, MSI for sending us three GTX 1080 Gaming cards in 2018.
For our testing on the 2020 suite, we have secured three RTX 2080 Ti GPUs direct from NVIDIA. These GPUs have been optimized for with drivers and in gaming titles, and given how rare our updates are, we are thankful for getting the high-end hardware. (It’s worth noting we won’t be updating to whatever RTX 3080 variant is coming out at some point for a while yet.)
On the topic of resolutions, this is something that has been hit and miss for us in the past. Some users state that they want to see the lowest resolution and lowest fidelity options, because this puts the most strain on the CPU, such as a 480p Ultra Low setting. In the past we have found this unrealistic for all use cases, and even if it does give the best shot for a difference in results, the actual point where you come GPU limited might be at a higher resolution. In our last test suite, we went from the 720p Ultra Low up to 1080p Medium, 1440p High, and 4K Ultra settings. However, our most vocal readers hated it, because even by 1080p medium, we were GPU limited for the most part.
So to that end, the benchmarks this time round attempt to follow the basic pattern where possible:
- Lowest Resolution with lowest scaling, Lowest Settings
- 2560x1440 with the lowest settings (1080p where not possible)
- 3840x2160 with the lowest settings
- 1920x1080 at the maximum settings
Point (1) should give the ultimate CPU limited scenario. We should see that lift as we move up through (2) 1440p and (3) 4K, with 4K low still being quite strenuous in some titles.
Point (4) is essentially our ‘real world’ test. The RTX 2080 Ti is overkill for 1080p Maximum, and we’ll see that most modern CPUs pull well over 60 FPS average in this scenario.
What will be interesting is that for some titles, 4K Low is more compute heavy than 1080p Maximum, and for other titles that relationship is reversed.
For integrated graphics testing, we use the (1) and (4) settings to see where the GPU lies with respect to CPU performance (1) as well as test to confirm just how close integrated graphics is to proper 1080p gaming (4).
So we have the following benchmarks as part of our script, automated to the point of a one-button run and out pops the results approximately 10 hours later, per GPU. Also listed are the resolutions and settings used.
Offline Games
- Chernobylite, 360p Low, 1440p Low, 4K Low, 1080p Max
- Civilization 6, 480p Low, 1440p Low, 4K Low, 1080p Max
- Deus Ex: Mankind Divided, 600p Low, 1440p Low, 4K Low, 1080p Max
- Final Fantasy XIV: 768p Min, 1440p Min, 4K Min, 1080p Max
- Final Fantasy XV: 720p Standard, 1080p Standard, 4K Standard, 8K Standard
- World of Tanks: 768p Min, 1080p Standard, 1080p Max, 4K Max
Online Games
- Borderlands 3, 360p VLow, 1440p VLow, 4K VLow, 1080p Badass
- F1 2019, 768p ULow, 1440p ULow, 4K ULow, 1080p Ultra
- Far Cry 5, 720p Low, 1440p Low, 4K Low, 1080p Ultra
- Gears Tactics, 720p Low, 4K Low, 8K Low 1080p Ultra
- Grand Theft Auto 5, 720p Low, 1440p Low, 4K Low, 1080p Max
- Red Dead Redemption 2, 384p Min, 1440p Min, 8K Min, 1080p Max
- Strange Brigade DX12, 720p Low, 1440p Low, 4K Low, 1080p Ultra
- Strange Brigade Vulkan, 720p Low, 1440p Low, 4K Low, 1080p Ultra
For each of the games in our testing, we take the frame times where we can (the two that we cannot are Chernobylite and FFXIV). For these games, at each resolution/setting combination, we run them for as many loops in a given time limit (often 10 minutes per resolution). Results are then taken as average frame rates and 95th percentiles.
If there are any game developers out there involved with any of the benchmarks above, please get in touch at ian@anandtech.com. I have a list of requests to make benchmarking your title easier! I have a literal document I’ve compiled showing what would be ideal, best practices, who gets it correct and who gets it wrong, etc.
The other angle is DRM, and some titles have limits of 5 systems per day. This may limit our testing in some cases; in other cases it is solvable.
Power Consumption
The nature of reporting processor power consumption has become, in part, a dystopian nightmare. Historically the peak power consumption of a processor, as purchased, is given by its Thermal Design Power (TDP, or PL1). For many markets, such as embedded processors, that value of TDP still signifies the peak power consumption. For the processors we test at AnandTech, either desktop, notebook, or enterprise, this is not always the case.
Modern high performance processors implement a feature called Turbo. This allows, usually for a limited time, a processor to go beyond its rated frequency. Exactly how far the processor goes depends on a few factors, such as the Turbo Power Limit (PL2), whether the peak frequency is hard coded, the thermals, and the power delivery. Turbo can sometimes be very aggressive, allowing power values 2.5x above the rated TDP.
AMD and Intel have different definitions for TDP, but are broadly speaking applied the same. The difference comes to turbo modes, turbo limits, turbo budgets, and how the processors manage that power balance. These topics are 10000-12000 word articles in their own right, and we’ve got a few articles worth reading on the topic.
- Why Intel Processors Draw More Power Than Expected: TDP and Turbo Explained
- Talking TDP, Turbo and Overclocking: An Interview with Intel Fellow Guy Therien
- Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics
- Intel’s TDP Shenanigans Hurts Everyone
In simple terms, processor manufacturers only ever guarantee two values which are tied together - when all cores are running at base frequency, the processor should be running at or below the TDP rating. All turbo modes and power modes above that are not covered by warranty. Intel kind of screwed this up with the Tiger Lake launch in September 2020, by refusing to define a TDP rating for its new processors, instead going for a range. Obfuscation like this is a frustrating endeavor for press and end-users alike.
However, for our tests in this review, we measure the power consumption of the processor in a variety of different scenarios. These include full AVX2/AVX512 (delete as applicable) workflows, real-world image-model construction, and others as appropriate. These tests are done as comparative models. We also note the peak power recorded in any of our tests.
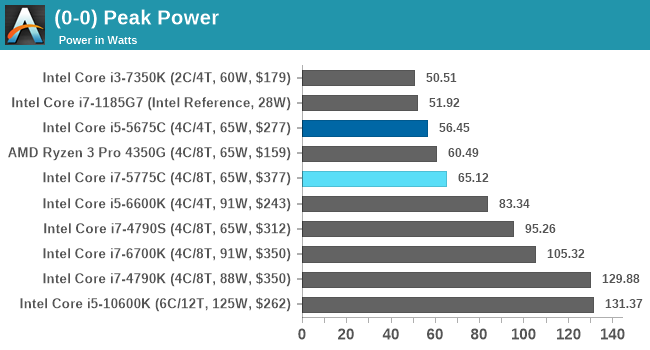
In peak power, the Core i7-5775C sticks to the 65 W value, whereas the Core i5 variant is below its TDP value. This is beyond the 22nm Core i7-4790S which is also a 65 W part.
In real-world tests, first up is our image-model construction workload, using our Agisoft Photoscan benchmark. This test has a number of different areas that involve single thread, multi-thread, or memory limited algorithms.
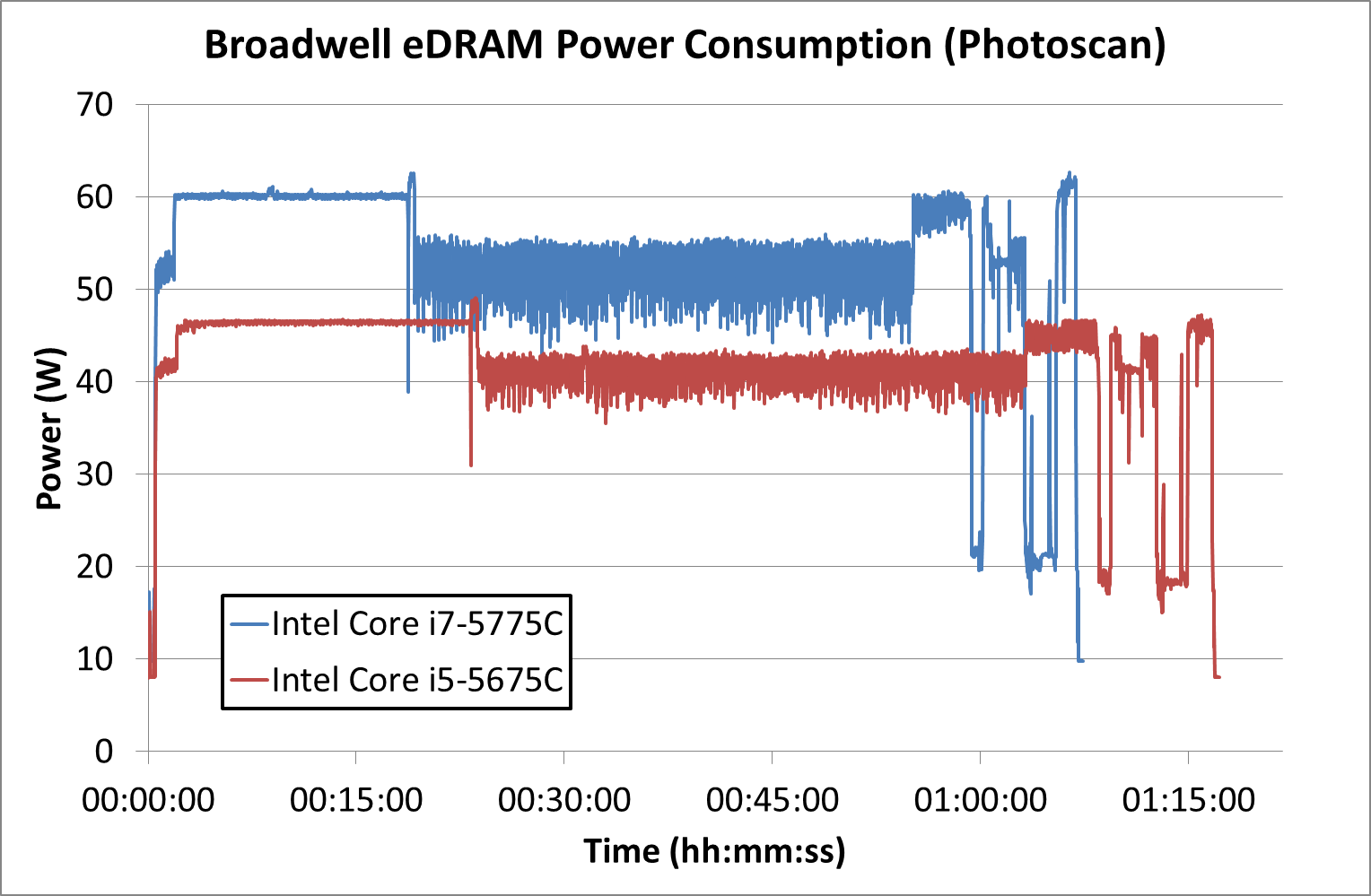
For Photoscan, the Core i7 spends its 'real world' time around 60 W, but does momentarily spike up above that 60 W mark. The Core i5 by comparison doesn't even touch 50 W.
The second test is from y-Cruncher, which is our AVX2/AVX512 workload. This also has some memory requirements, which can lead to periodic cycling with systems that have lower memory bandwidth per core options.
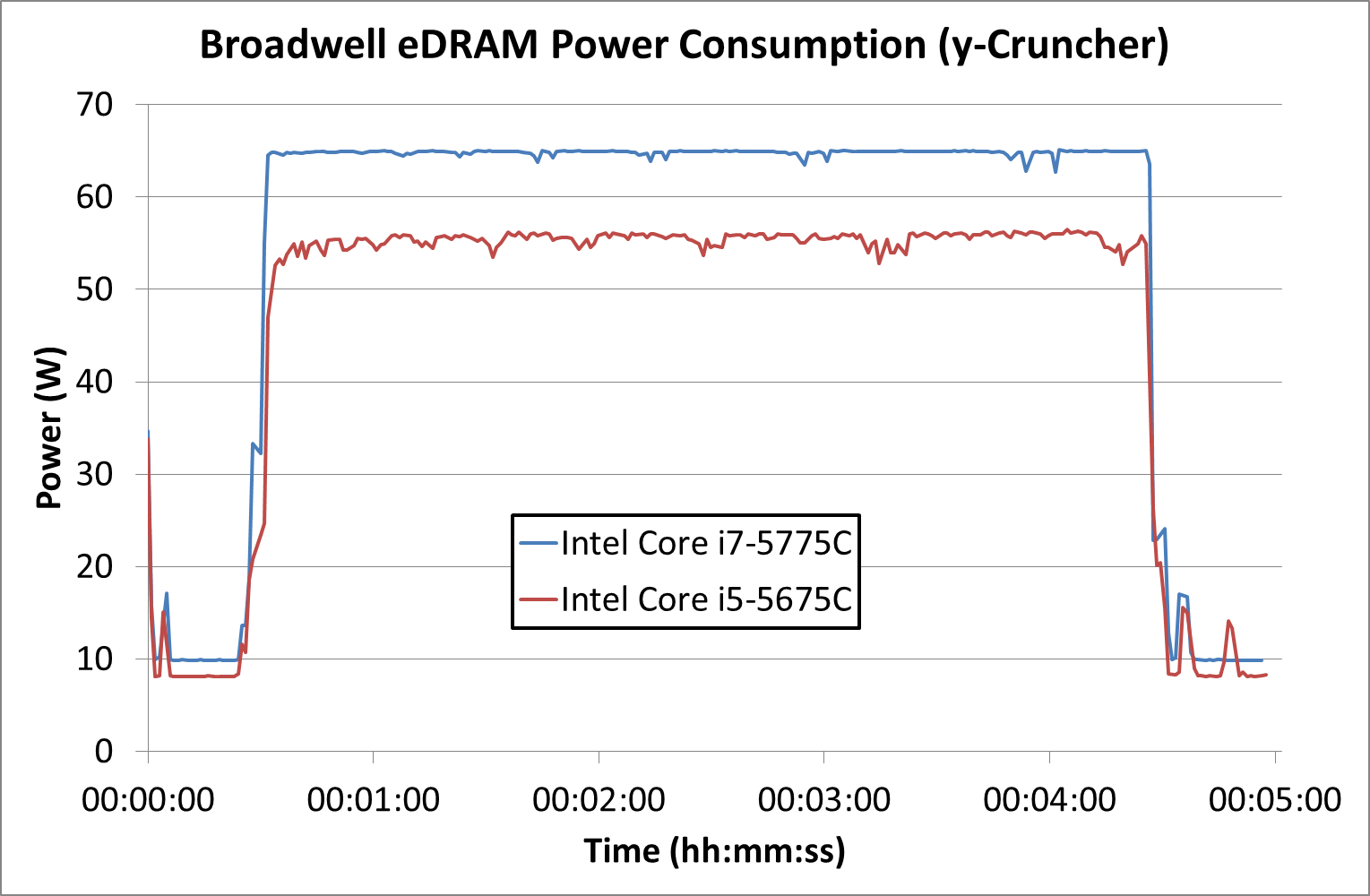
We're seeing some slight variation in power as the y-Cruncher algortihm moves out to DRAM movement over compute, however both processors seem to be hitting either their power limits or just a natural peak power consumption.
CPU Tests: Office and Science
Our previous set of ‘office’ benchmarks have often been a mix of science and synthetics, so this time we wanted to keep our office section purely on real world performance.
Agisoft Photoscan 1.3.3: link
The concept of Photoscan is about translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the final 3D model in both spatial accuracy and texturing accuracy. The algorithm has four stages, with some parts of the stages being single-threaded and others multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.

For the update to version 1.3.3, the Agisoft software now supports command line operation. Agisoft provided us with a set of new images for this version of the test, and a python script to run it. We’ve modified the script slightly by changing some quality settings for the sake of the benchmark suite length, as well as adjusting how the final timing data is recorded. The python script dumps the results file in the format of our choosing. For our test we obtain the time for each stage of the benchmark, as well as the overall time.

The extra power budget of the Devil's Canyon pulls ahead of the Core i7-5775C.
Application Opening: GIMP 2.10.18
First up is a test using a monstrous multi-layered xcf file to load GIMP. While the file is only a single ‘image’, it has so many high-quality layers embedded it was taking north of 15 seconds to open and to gain control on the mid-range notebook I was using at the time.
What we test here is the first run - normally on the first time a user loads the GIMP package from a fresh install, the system has to configure a few dozen files that remain optimized on subsequent opening. For our test we delete those configured optimized files in order to force a ‘fresh load’ each time the software in run.
We measure the time taken from calling the software to be opened, and until the software hands itself back over to the OS for user control. The test is repeated for a minimum of ten minutes or at least 15 loops, whichever comes first, with the first three results discarded.
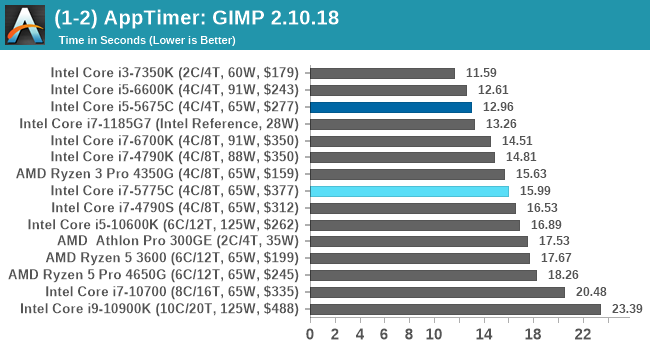
GIMP does optimizations for every CPU thread in the system, which requires that higher thread-count processors take a lot longer to run.
Science
In this version of our test suite, all the science focused tests that aren’t ‘simulation’ work are now in our science section. This includes Brownian Motion, calculating digits of Pi, molecular dynamics, and for the first time, we’re trialing an artificial intelligence benchmark, both inference and training, that works under Windows using python and TensorFlow. Where possible these benchmarks have been optimized with the latest in vector instructions, except for the AI test – we were told that while it uses Intel’s Math Kernel Libraries, they’re optimized more for Linux than for Windows, and so it gives an interesting result when unoptimized software is used.
3D Particle Movement v2.1: Non-AVX and AVX2/AVX512
This is the latest version of this benchmark designed to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. This involves randomly moving particles in a 3D space using a set of algorithms that define random movement. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in.
The initial version of v2.1 is a custom C++ binary of my own code, and flags are in place to allow for multiple loops of the code with a custom benchmark length. By default this version runs six times and outputs the average score to the console, which we capture with a redirection operator that writes to file.
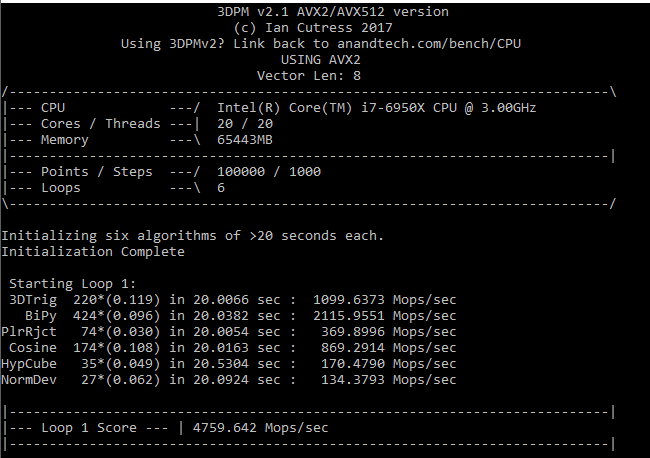
For v2.1, we also have a fully optimized AVX2/AVX512 version, which uses intrinsics to get the best performance out of the software. This was done by a former Intel AVX-512 engineer who now works elsewhere. According to Jim Keller, there are only a couple dozen or so people who understand how to extract the best performance out of a CPU, and this guy is one of them. To keep things honest, AMD also has a copy of the code, but has not proposed any changes.
The 3DPM test is set to output millions of movements per second, rather than time to complete a fixed number of movements.
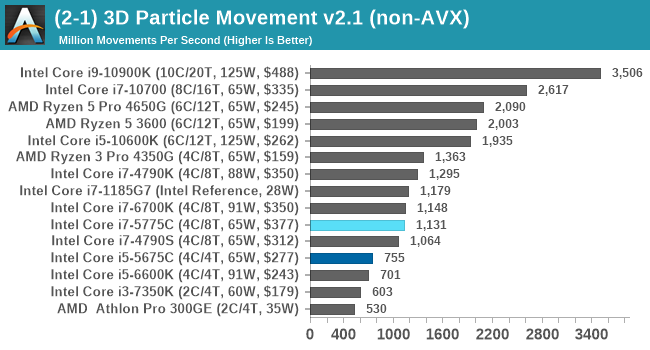
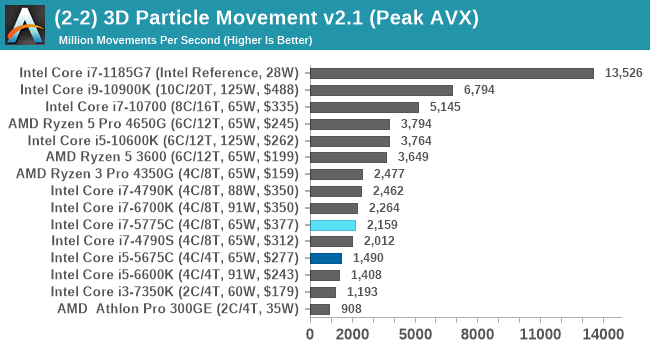
3DPM isn't memory limited, and as a result we see a relative natural order of performance.
y-Cruncher 0.78.9506: www.numberworld.org/y-cruncher
If you ask anyone what sort of computer holds the world record for calculating the most digits of pi, I can guarantee that a good portion of those answers might point to some colossus super computer built into a mountain by a super-villain. Fortunately nothing could be further from the truth – the computer with the record is a quad socket Ivy Bridge server with 300 TB of storage. The software that was run to get that was y-cruncher.
Built by Alex Yee over the last part of a decade and some more, y-Cruncher is the software of choice for calculating billions and trillions of digits of the most popular mathematical constants. The software has held the world record for Pi since August 2010, and has broken the record a total of 7 times since. It also holds records for e, the Golden Ratio, and others. According to Alex, the program runs around 500,000 lines of code, and he has multiple binaries each optimized for different families of processors, such as Zen, Ice Lake, Sky Lake, all the way back to Nehalem, using the latest SSE/AVX2/AVX512 instructions where they fit in, and then further optimized for how each core is built.
For our purposes, we’re calculating Pi, as it is more compute bound than memory bound. In single thread mode we calculate 250 million digits, while in multithreaded mode we go for 2.5 billion digits. That 2.5 billion digit value requires ~12 GB of DRAM, and so is limited to systems with at least 16 GB.
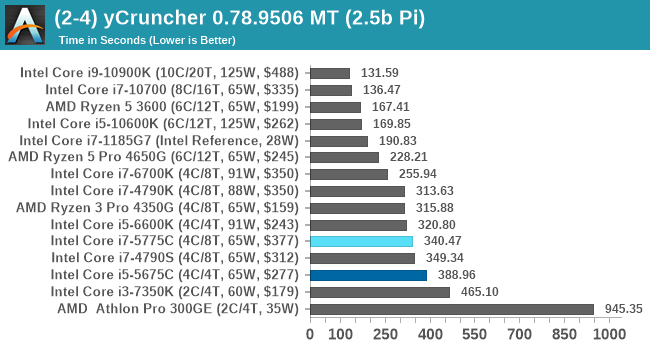
Despite being a more memory driven benchmark, y-Cruncher here follows a more traditional performance order.
NAMD 2.13 (ApoA1): Molecular Dynamics
One of the popular science fields is modeling the dynamics of proteins. By looking at how the energy of active sites within a large protein structure over time, scientists behind the research can calculate required activation energies for potential interactions. This becomes very important in drug discovery. Molecular dynamics also plays a large role in protein folding, and in understanding what happens when proteins misfold, and what can be done to prevent it. Two of the most popular molecular dynamics packages in use today are NAMD and GROMACS.
NAMD, or Nanoscale Molecular Dynamics, has already been used in extensive Coronavirus research on the Frontier supercomputer. Typical simulations using the package are measured in how many nanoseconds per day can be calculated with the given hardware, and the ApoA1 protein (92,224 atoms) has been the standard model for molecular dynamics simulation.
Luckily the compute can home in on a typical ‘nanoseconds-per-day’ rate after only 60 seconds of simulation, however we stretch that out to 10 minutes to take a more sustained value, as by that time most turbo limits should be surpassed. The simulation itself works with 2 femtosecond timesteps. We use version 2.13 as this was the recommended version at the time of integrating this benchmark into our suite. The latest nightly builds we’re aware have started to enable support for AVX-512, however due to consistency in our benchmark suite, we are retaining with 2.13. Other software that we test with has AVX-512 acceleration.
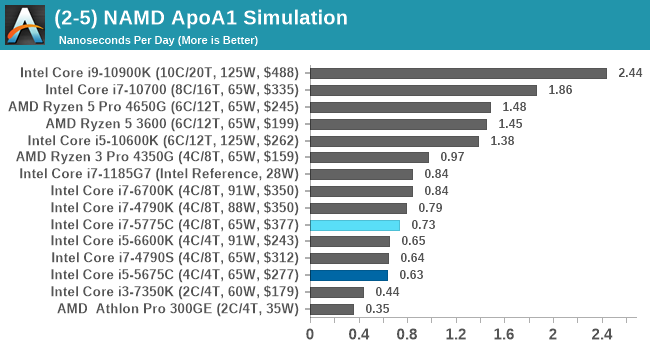
Similar to y-Cruncher, the extra DRAM doesn't afford any benefits for NAMD on this scale. The Devil's Canyon Core i7-4790K is still ahead of the Broadwell i7.
AI Benchmark 0.1.2 using TensorFlow: Link
Finding an appropriate artificial intelligence benchmark for Windows has been a holy grail of mine for quite a while. The problem is that AI is such a fast moving, fast paced word that whatever I compute this quarter will no longer be relevant in the next, and one of the key metrics in this benchmarking suite is being able to keep data over a long period of time. We’ve had AI benchmarks on smartphones for a while, given that smartphones are a better target for AI workloads, but it also makes some sense that everything on PC is geared towards Linux as well.
Thankfully however, the good folks over at ETH Zurich in Switzerland have converted their smartphone AI benchmark into something that’s useable in Windows. It uses TensorFlow, and for our benchmark purposes we’ve locked our testing down to TensorFlow 2.10, AI Benchmark 0.1.2, while using Python 3.7.6.

The benchmark runs through 19 different networks including MobileNet-V2, ResNet-V2, VGG-19 Super-Res, NVIDIA-SPADE, PSPNet, DeepLab, Pixel-RNN, and GNMT-Translation. All the tests probe both the inference and the training at various input sizes and batch sizes, except the translation that only does inference. It measures the time taken to do a given amount of work, and spits out a value at the end.
There is one big caveat for all of this, however. Speaking with the folks over at ETH, they use Intel’s Math Kernel Libraries (MKL) for Windows, and they’re seeing some incredible drawbacks. I was told that MKL for Windows doesn’t play well with multiple threads, and as a result any Windows results are going to perform a lot worse than Linux results. On top of that, after a given number of threads (~16), MKL kind of gives up and performance drops of quite substantially.
So why test it at all? Firstly, because we need an AI benchmark, and a bad one is still better than not having one at all. Secondly, if MKL on Windows is the problem, then by publicizing the test, it might just put a boot somewhere for MKL to get fixed. To that end, we’ll stay with the benchmark as long as it remains feasible.
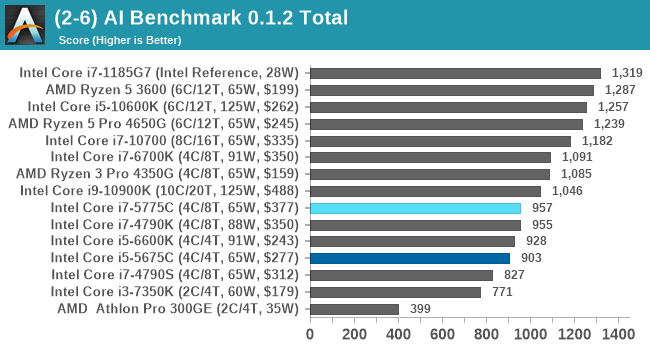
The AI-Benchmark (ETH) doesn't necessarily follow a standard performance candence due to MKL on Windows, but the Broadwell parts both score under 1000 pts here.
CPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
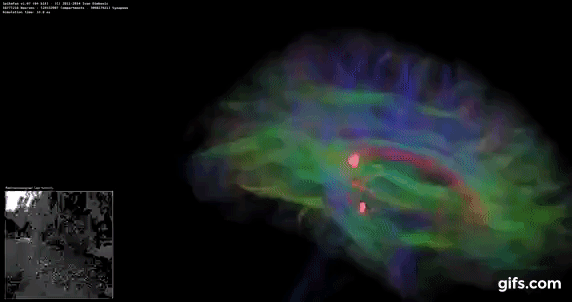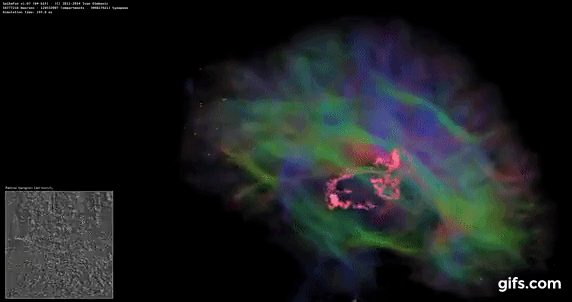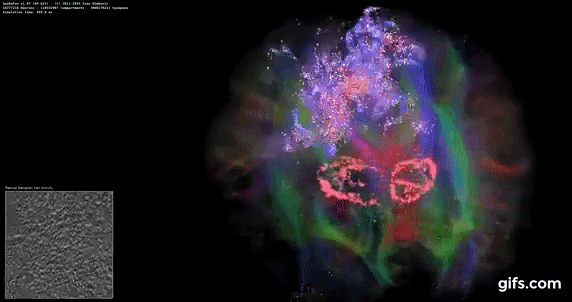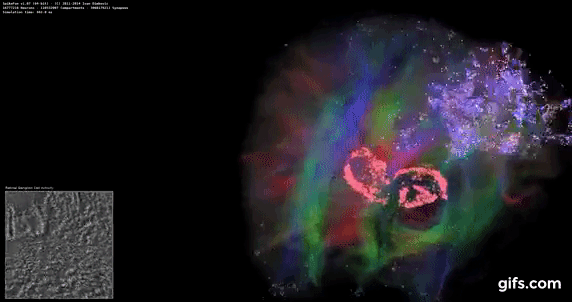
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.
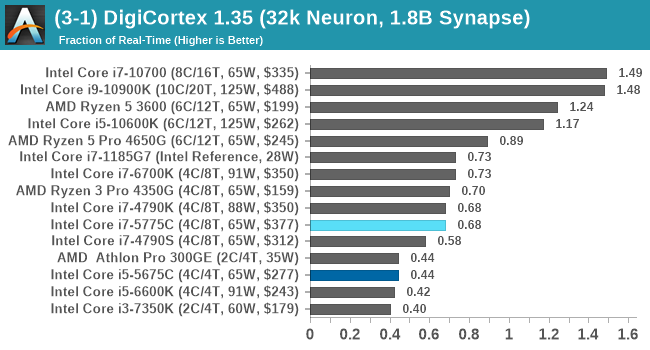
DigiCortex seems to fall into layers of performance, and the Core i7-5775C, with DDR3-1600, comes very close to the Core i7-6700K with DDR4-2133.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts
DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.
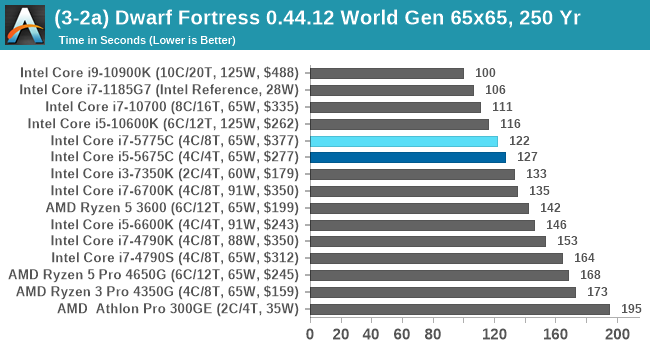
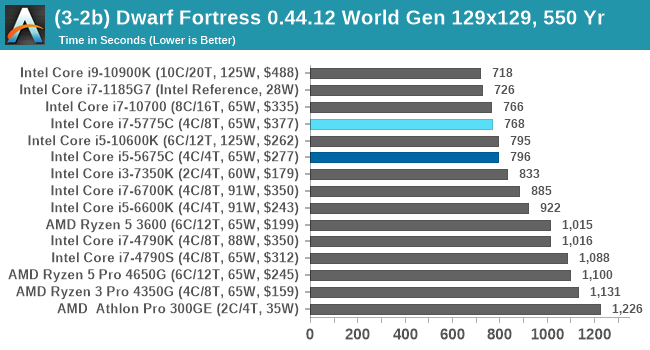
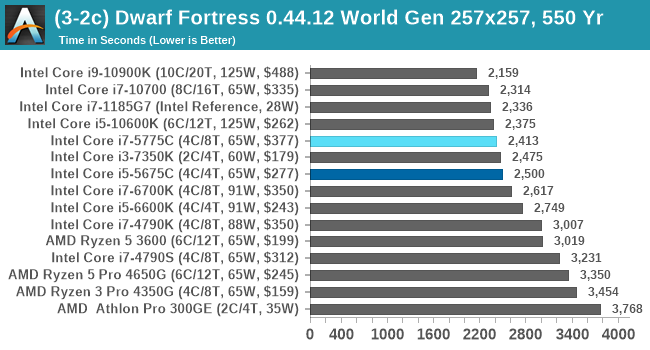
Here's where we start to see some of the benefits of the lower latency eDRAM out to 128 MB. That larger cache pushes both Broadwell parts very near to modern CPUs, putting all the older models down the list. This is something AMD's APUs aren't particularly good at, due to the very limited L3 cache in play.
Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.
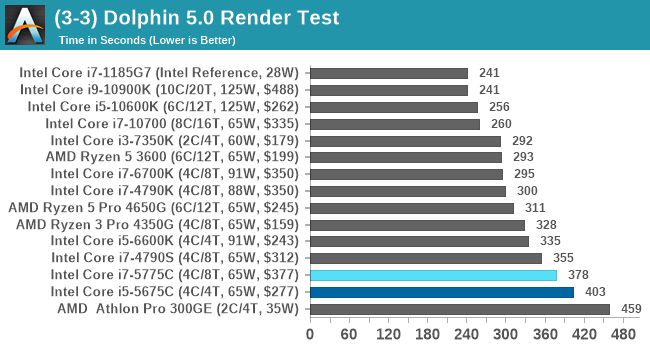
Unfortunately Dolphin isn't a fan of the eDRAM versions.
CPU Tests: Rendering
Rendering tests, compared to others, are often a little more simple to digest and automate. All the tests put out some sort of score or time, usually in an obtainable way that makes it fairly easy to extract. These tests are some of the most strenuous in our list, due to the highly threaded nature of rendering and ray-tracing, and can draw a lot of power. If a system is not properly configured to deal with the thermal requirements of the processor, the rendering benchmarks is where it would show most easily as the frequency drops over a sustained period of time. Most benchmarks in this case are re-run several times, and the key to this is having an appropriate idle/wait time between benchmarks to allow for temperatures to normalize from the last test.
Blender 2.83 LTS: Link
One of the popular tools for rendering is Blender, with it being a public open source project that anyone in the animation industry can get involved in. This extends to conferences, use in films and VR, with a dedicated Blender Institute, and everything you might expect from a professional software package (except perhaps a professional grade support package). With it being open-source, studios can customize it in as many ways as they need to get the results they require. It ends up being a big optimization target for both Intel and AMD in this regard.
For benchmarking purposes, we fell back to one rendering a frame from a detailed project. Most reviews, as we have done in the past, focus on one of the classic Blender renders, known as BMW_27. It can take anywhere from a few minutes to almost an hour on a regular system. However now that Blender has moved onto a Long Term Support model (LTS) with the latest 2.83 release, we decided to go for something different.

We use this scene, called PartyTug at 6AM by Ian Hubert, which is the official image of Blender 2.83. It is 44.3 MB in size, and uses some of the more modern compute properties of Blender. As it is more complex than the BMW scene, but uses different aspects of the compute model, time to process is roughly similar to before. We loop the scene for at least 10 minutes, taking the average time of the completions taken. Blender offers a command-line tool for batch commands, and we redirect the output into a text file.

Blender is more performance oriented, so we see a more standard performance profile. The Broadwell performs akin to Tiger Lake here only by virtue of the 28W sustained power limit on Tiger Lake.
Corona 1.3: Link
Corona is billed as a popular high-performance photorealistic rendering engine for 3ds Max, with development for Cinema 4D support as well. In order to promote the software, the developers produced a downloadable benchmark on the 1.3 version of the software, with a ray-traced scene involving a military vehicle and a lot of foliage. The software does multiple passes, calculating the scene, geometry, preconditioning and rendering, with performance measured in the time to finish the benchmark (the official metric used on their website) or in rays per second (the metric we use to offer a more linear scale).
The standard benchmark provided by Corona is interface driven: the scene is calculated and displayed in front of the user, with the ability to upload the result to their online database. We got in contact with the developers, who provided us with a non-interface version that allowed for command-line entry and retrieval of the results very easily. We loop around the benchmark five times, waiting 60 seconds between each, and taking an overall average. The time to run this benchmark can be around 10 minutes on a Core i9, up to over an hour on a quad-core 2014 AMD processor or dual-core Pentium.
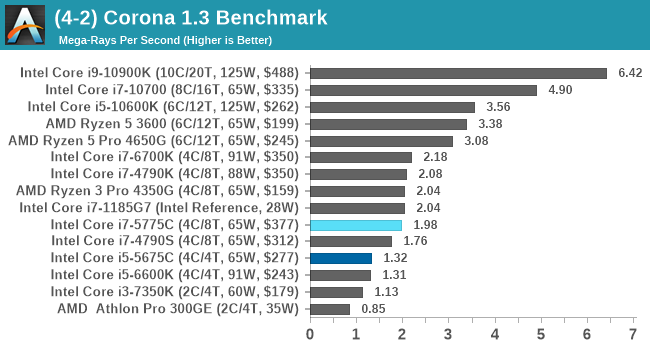
Similarly, Corona has no need for the eDRAM.
Crysis CPU-Only Gameplay
One of the most oft used memes in computer gaming is ‘Can It Run Crysis?’. The original 2007 game, built in the Crytek engine by Crytek, was heralded as a computationally complex title for the hardware at the time and several years after, suggesting that a user needed graphics hardware from the future in order to run it. Fast forward over a decade, and the game runs fairly easily on modern GPUs.
But can we also apply the same concept to pure CPU rendering? Can a CPU, on its own, render Crysis? Since 64 core processors entered the market, one can dream. So we built a benchmark to see whether the hardware can.
For this test, we’re running Crysis’ own GPU benchmark, but in CPU render mode. This is a 2000 frame test, with medium settings.

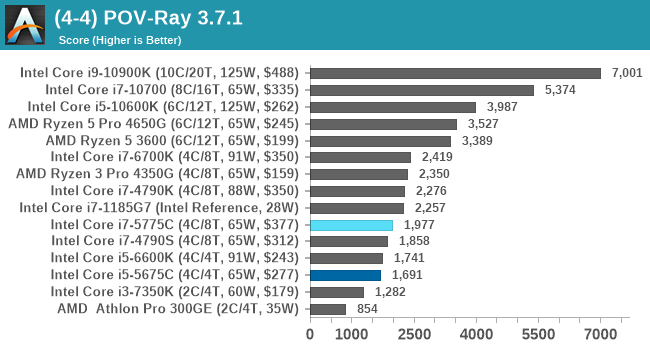
POV-Ray 3.7.1: Link
A long time benchmark staple, POV-Ray is another rendering program that is well known to load up every single thread in a system, regardless of cache and memory levels. After a long period of POV-Ray 3.7 being the latest official release, when AMD launched Ryzen the POV-Ray codebase suddenly saw a range of activity from both AMD and Intel, knowing that the software (with the built-in benchmark) would be an optimization tool for the hardware.
We had to stick a flag in the sand when it came to selecting the version that was fair to both AMD and Intel, and still relevant to end-users. Version 3.7.1 fixes a significant bug in the early 2017 code that was advised against in both Intel and AMD manuals regarding to write-after-read, leading to a nice performance boost.

The benchmark can take over 20 minutes on a slow system with few cores, or around a minute or two on a fast system, or seconds with a dual high-core count EPYC. Because POV-Ray draws a large amount of power and current, it is important to make sure the cooling is sufficient here and the system stays in its high-power state. Using a motherboard with a poor power-delivery and low airflow could create an issue that won’t be obvious in some CPU positioning if the power limit only causes a 100 MHz drop as it changes P-states.
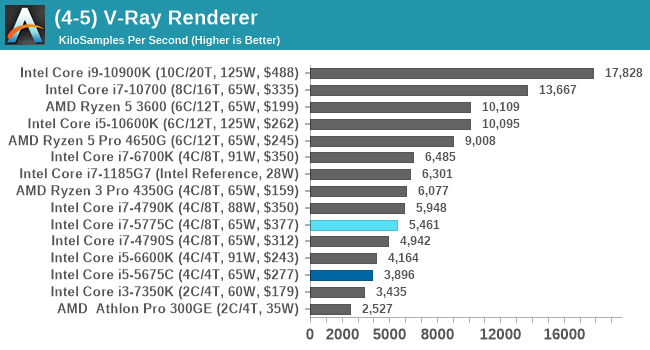
V-Ray: Link
We have a couple of renderers and ray tracers in our suite already, however V-Ray’s benchmark came through for a requested benchmark enough for us to roll it into our suite. Built by ChaosGroup, V-Ray is a 3D rendering package compatible with a number of popular commercial imaging applications, such as 3ds Max, Maya, Undreal, Cinema 4D, and Blender.

We run the standard standalone benchmark application, but in an automated fashion to pull out the result in the form of kilosamples/second. We run the test six times and take an average of the valid results.
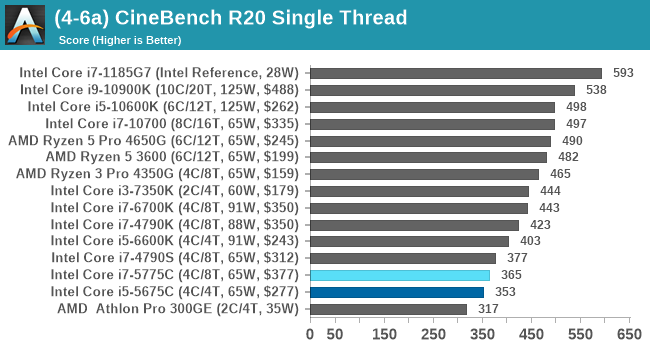
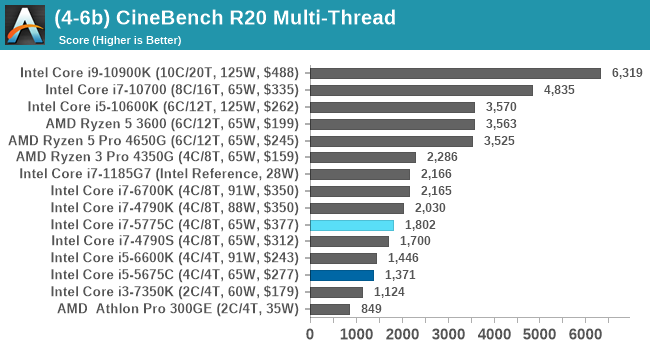
Cinebench R20: Link
Another common stable of a benchmark suite is Cinebench. Based on Cinema4D, Cinebench is a purpose built benchmark machine that renders a scene with both single and multi-threaded options. The scene is identical in both cases. The R20 version means that it targets Cinema 4D R20, a slightly older version of the software which is currently on version R21. Cinebench R20 was launched given that the R15 version had been out a long time, and despite the difference between the benchmark and the latest version of the software on which it is based, Cinebench results are often quoted a lot in marketing materials.
Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath. The results are output as a score from the software, which is directly proportional to the time taken. Using the benchmark flags for single CPU and multi-CPU workloads, we run the software from the command line which opens the test, runs it, and dumps the result into the console which is redirected to a text file. The test is repeated for a minimum of 10 minutes for both ST and MT, and then the runs averaged.
CPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
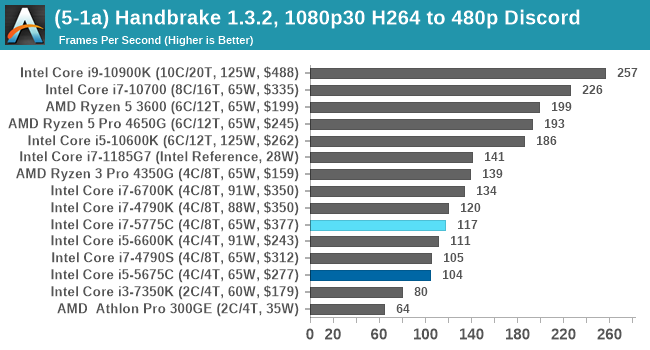
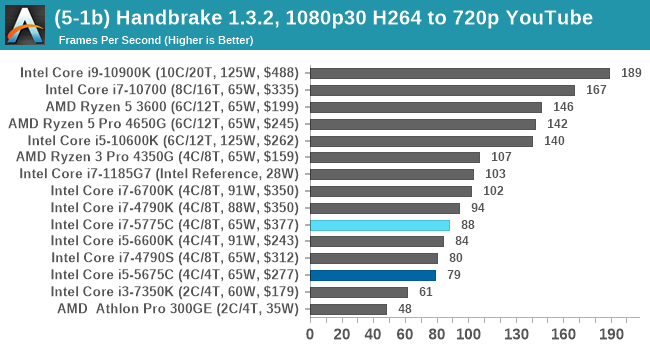
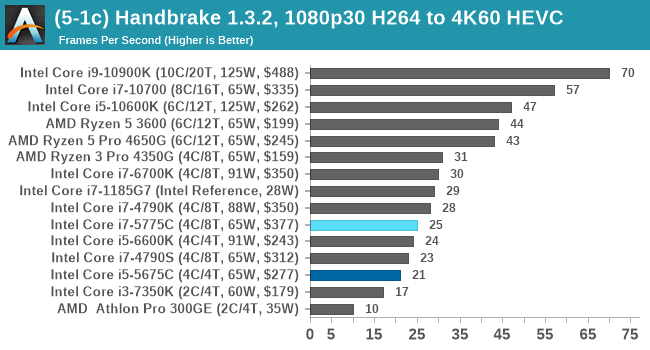
The larger caches aren't that helpful when it comes to CPU video encoding.
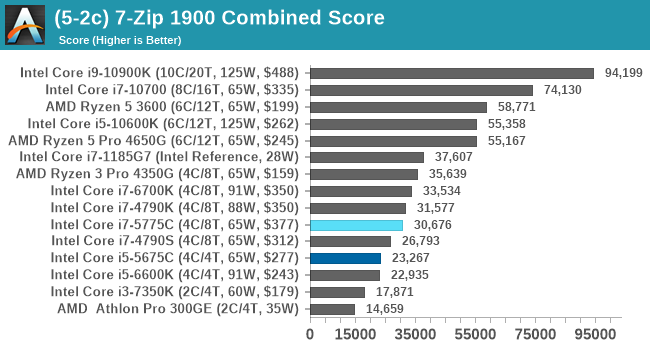
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.
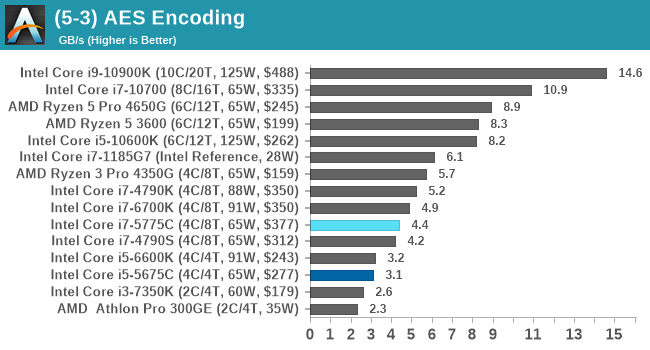
AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.
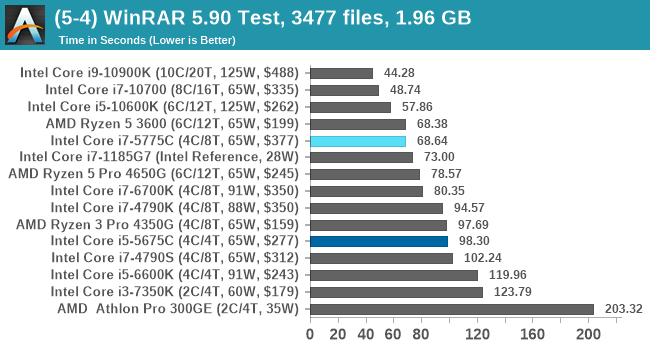
Similar to our original Broadwell review, the Core i7 here punches well above its weight as WinRAR can keep more of the dictionary required for compression on hand, as well as having a very linear prefetch chain that it can keep close to the core.
CPU Tests: Legacy and Web
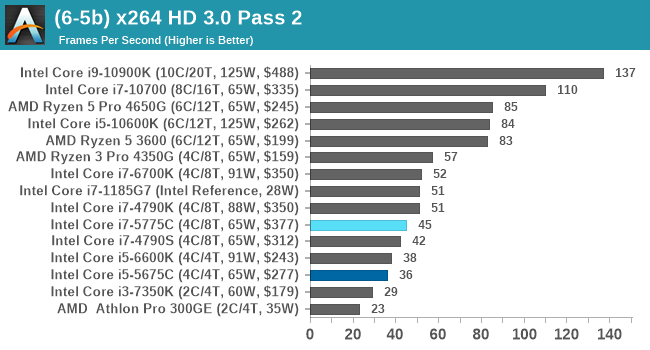
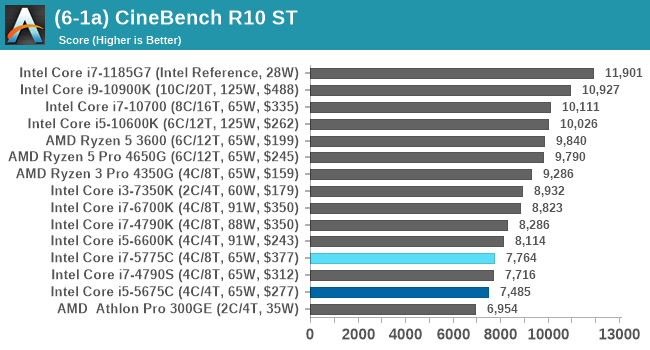
In order to gather data to compare with older benchmarks, we are still keeping a number of tests under our ‘legacy’ section. This includes all the former major versions of CineBench (R15, R11.5, R10) as well as x264 HD 3.0 and the first very naïve version of 3DPM v2.1. We won’t be transferring the data over from the old testing into Bench, otherwise it would be populated with 200 CPUs with only one data point, so it will fill up as we test more CPUs like the others.
The other section here is our web tests.
Web Tests: Kraken, Octane, and Speedometer
Benchmarking using web tools is always a bit difficult. Browsers change almost daily, and the way the web is used changes even quicker. While there is some scope for advanced computational based benchmarks, most users care about responsiveness, which requires a strong back-end to work quickly to provide on the front-end. The benchmarks we chose for our web tests are essentially industry standards – at least once upon a time.
It should be noted that for each test, the browser is closed and re-opened a new with a fresh cache. We use a fixed Chromium version for our tests with the update capabilities removed to ensure consistency.
Mozilla Kraken 1.1
Kraken is a 2010 benchmark from Mozilla and does a series of JavaScript tests. These tests are a little more involved than previous tests, looking at artificial intelligence, audio manipulation, image manipulation, json parsing, and cryptographic functions. The benchmark starts with an initial download of data for the audio and imaging, and then runs through 10 times giving a timed result.

We loop through the 10-run test four times (so that’s a total of 40 runs), and average the four end-results. The result is given as time to complete the test, and we’re reaching a slow asymptotic limit with regards the highest IPC processors.
Google Octane 2.0
Our second test is also JavaScript based, but uses a lot more variation of newer JS techniques, such as object-oriented programming, kernel simulation, object creation/destruction, garbage collection, array manipulations, compiler latency and code execution.
Octane was developed after the discontinuation of other tests, with the goal of being more web-like than previous tests. It has been a popular benchmark, making it an obvious target for optimizations in the JavaScript engines. Ultimately it was retired in early 2017 due to this, although it is still widely used as a tool to determine general CPU performance in a number of web tasks.

Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a test over a series of JavaScript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics.
We repeat over the benchmark for a dozen loops, taking the average of the last five.

Legacy Tests

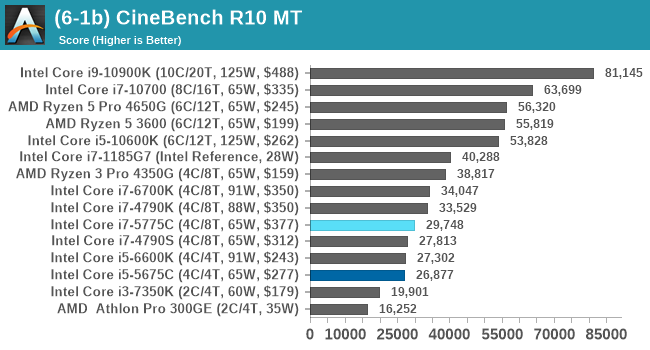
CPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.

AMD's processors, and Intel AVX512, have sha256 acceleration, however this doesn't help Broadwell.
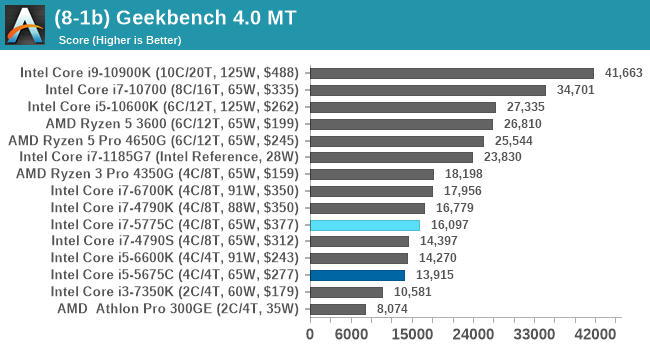
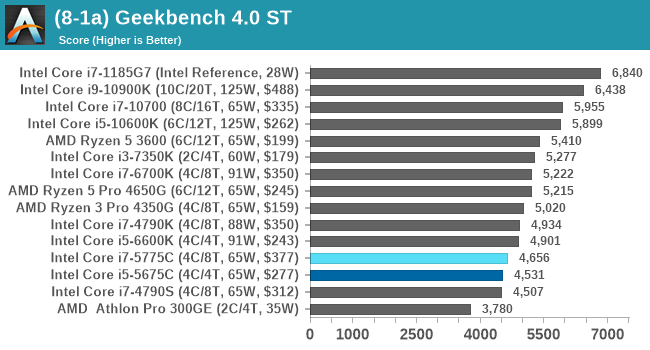
GeekBench: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We have both GB5 and GB4 results in our benchmark database. GB5 was introduced to our test suite after already having tested ~25 CPUs, and so the results are a little sporadic by comparison. These spots will be filled in when we retest any of the CPUs.
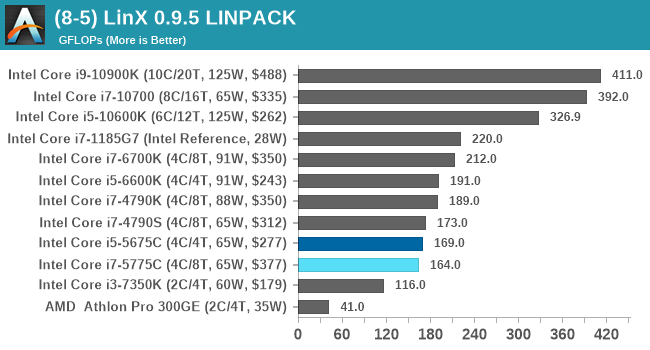
LinX 0.9.5 LINPACK
One of the benchmarks I’ve been after for a while is just something that outputs a very simple GFLOPs FP64 number, or in the case of AI I’d like to get a value for TOPs at a given level of quantization (FP32/FP16/INT8 etc). The most popular tool for doing this on supercomputers is a form of LINPACK, however for consumer systems it’s a case of making sure that the software is optimized for each CPU.
LinX has been a popular interface for LINPACK on Windows for a number of years. However the last official version was 0.6.5, launched in 2015, before the latest Ryzen hardware came into being. HWTips in Korea has been updating LinX and has separated out into two versions, one for Intel and one for AMD, and both have reached version 0.9.5. Unfortunately the AMD version is still a work in progress, as it doesn’t work on Zen 2.
There does exist a program called Linpack Extreme 1.1.3, which claims to be updated to use the latest version of the Intel Math Kernel Libraries. It works great, however the way the interface has been designed means that it can’t be automated for our uses, so we can’t use it.
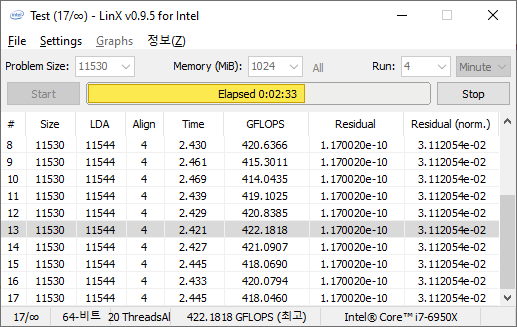
For LinX 0.9.5, there also is a difficulty of what parameters to put into LINPACK. The two main parameters are problem size and time – choose a problem size too small, and you won’t get peak performance. Choose it too large, and the calculation can go on for hours. To that end, we use the following algorithms as a compromise:
- Memory Use = Floor(1000 + 20*sqrt(threads)) MB
- Time = Floor(10+sqrt(threads)) minutes
For a 4 thread system, we use 1040 MB and run for 12 minutes.
For a 128 thread system, we use 1226 MB and run for 21 minutes.
CPU Tests: SPEC
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 8.0.0-svn350067-1~exp1+0~20181226174230.701~1.gbp6019f2 (trunk)
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
For each of the SPEC targets we are doing, SPEC2006 rate-1, SPEC2017 speed-1, and SPEC2017 speed-N, rather than publish all the separate test data in our reviews, we are going to condense it down into a few interesting data points. The full per-test values are in our benchmark database.
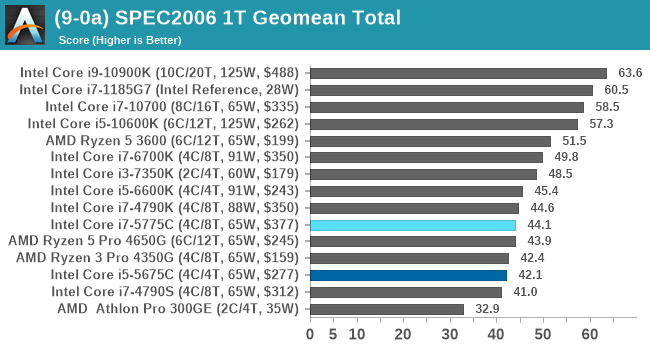
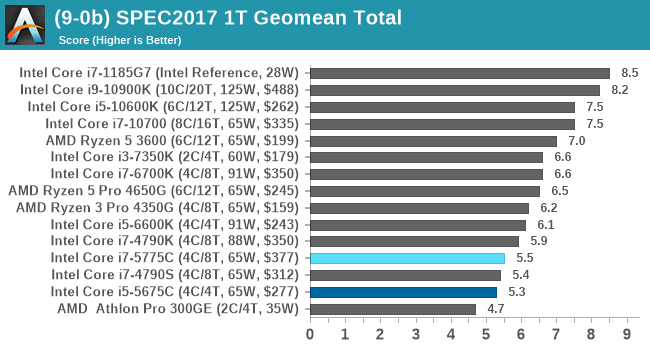
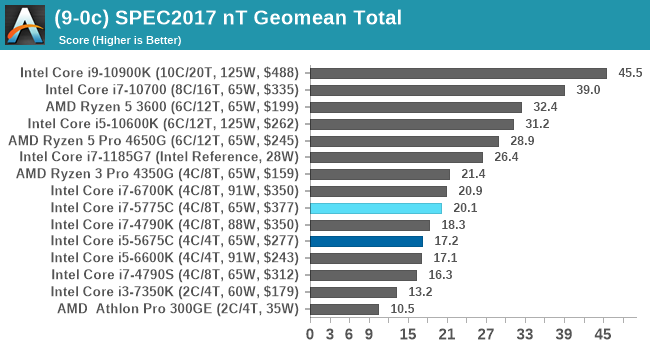
There are some specific tests that the eDRAM gets a sizeable boost in performance for, such as 471.omnetpp in SPEC2006 (+23% over 6700K). The main gains are in SPEC2017 nT, in 510.parest_r (+49%), 519.lbm_r (+63%), and 554.roms_r (+46%). However, the lower power and lower frequency still hamper the processors in a lot of scenarios.
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
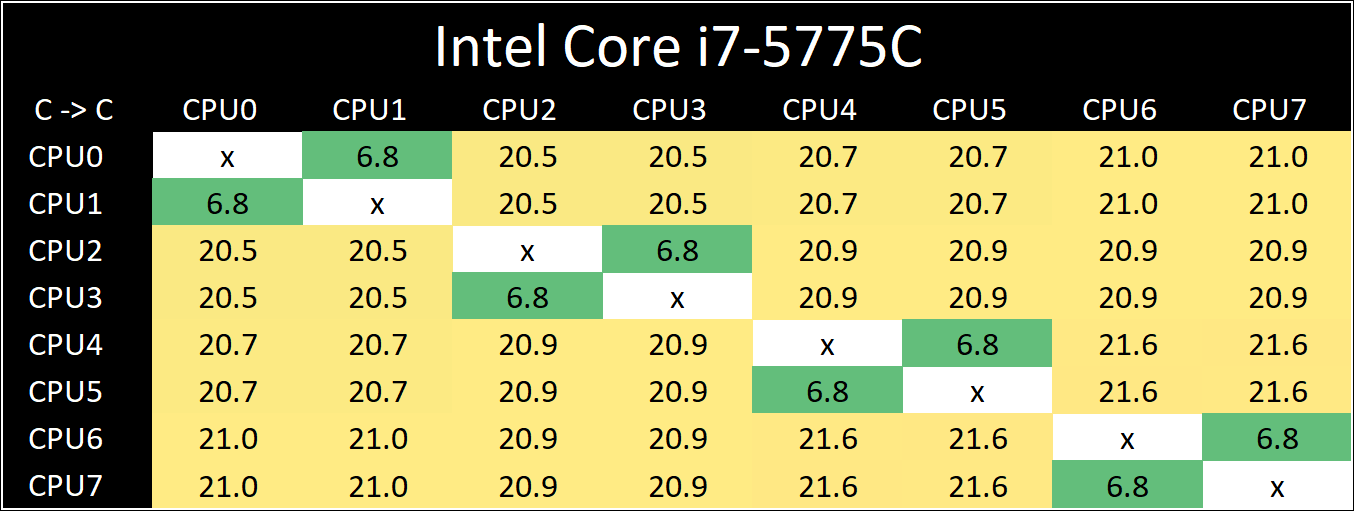
Broadwell is a familiar design, with all four cores connected in a ring-bus topology.
Cache-to-DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
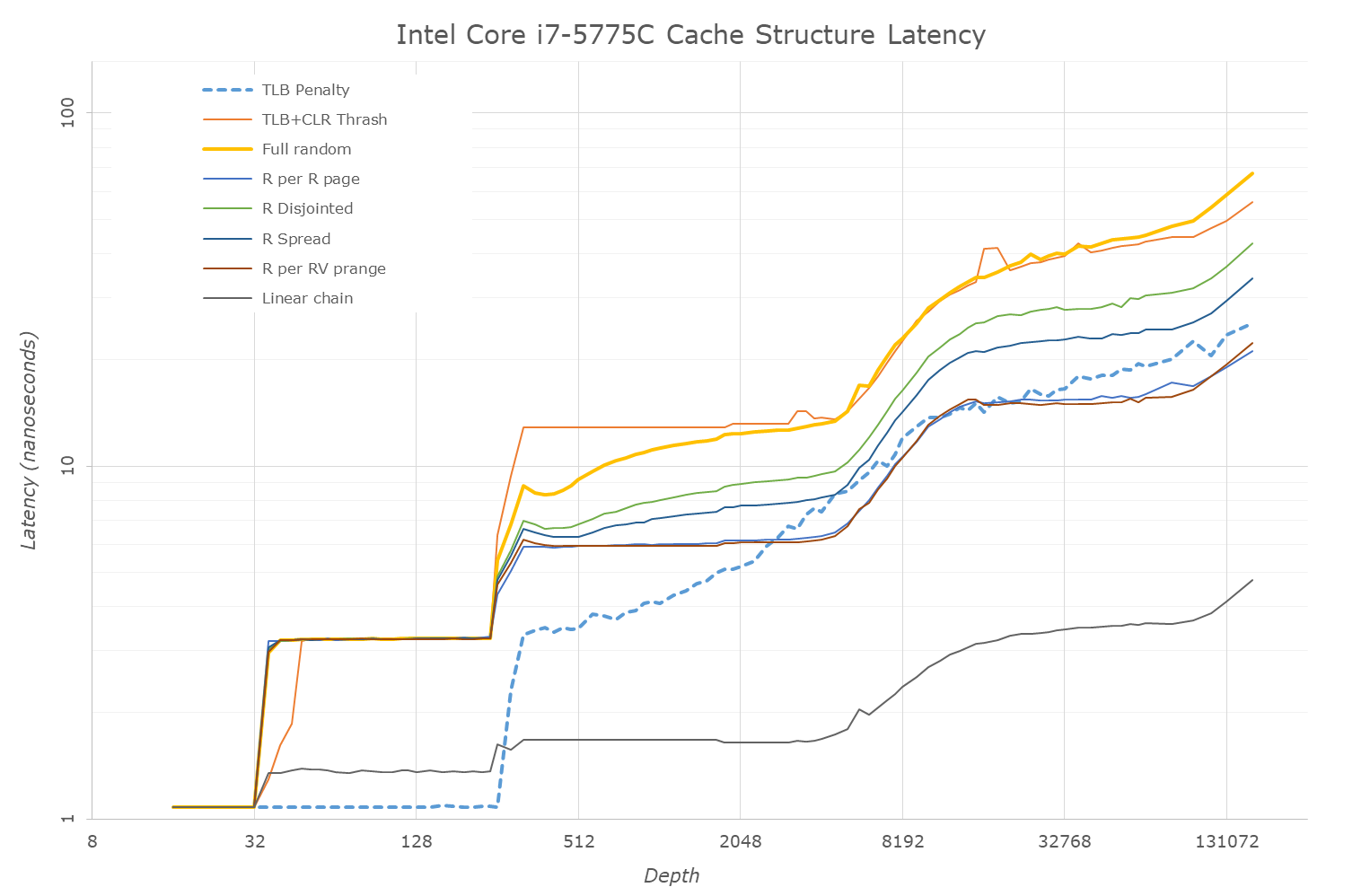
Our data shows a 4-cycle L1, a 12-cycle L2, a 26-50 cycle L3, while the eDRAM has a wide range from 50-150 cycles. This is still quicker than main memory, which goes to 200+ cycles.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.

From an idle frequency of 800 MHz, It takes ~32 ms for Intel to boost to 2.0 GHz, then another ~32 ms to get to 3.7 GHz. We’re essentially looking at 4 frames at 60 Hz to hit those high frequencies.
A y-Cruncher Sprint
The y-cruncher website has a large about of benchmark data showing how different CPUs perform to calculate specific values of pi. Below these there are a few CPUs where it shows the time to compute moving from 25 million digits to 50 million, 100 million, 250 million, and all the way up to 10 billion, to showcase how the performance scales with digits (assuming everything is in memory). This range of results, from 25 million to 250 billion, is something I’ve dubbed a ‘sprint’.
I have written some code in order to perform a sprint on every CPU we test. It detects the DRAM, works out the biggest value that can be calculated with that amount of memory, and works up from 25 million digits. For the tests that go up to the ~25 billion digits, it only adds an extra 15 minutes to the suite for an 8-core Ryzen CPU.
With this test, we can see the effect of increasing memory requirements on the workload and the scaling factor for a workload such as this.
- MT 25m: 1.617s
- MT 50m: 3.639s
- MT 100m: 8.156s
- MT 250m: 24.050s
- MT 500m: 53.525s
- MT 1000m: 118.651s
- MT 2500m: 341.330s
The scaling here isn’t linear – moving from 25m to 2.5b, we should see a 100x time increase, but instead it is 211x.
Gaming Tests: Chernobylite
Despite the advent of recent TV shows like Chernobyl, recreating the situation revolving around the 1986 Chernobyl nuclear disaster, the concept of nuclear fallout and the town of Pripyat have been popular settings for a number of games – mostly first person shooters. Chernobylite is an indie title that plays on a science-fiction survival horror experience and uses a 3D-scanned recreation of the real Chernobyl Exclusion Zone. It involves challenging combat, a mix of free exploration with crafting and non-linear story telling. While still in early access, it is already picking up plenty of awards.

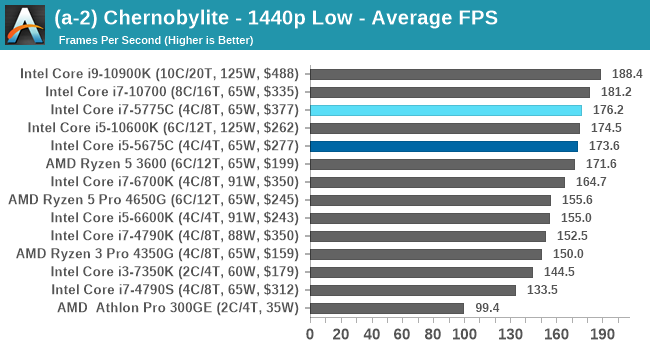
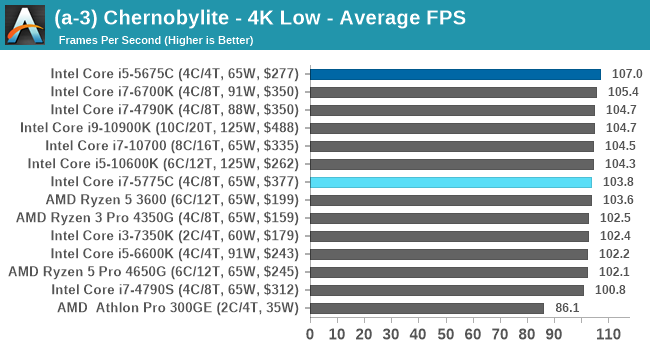
I picked up Chernobylite while still in early access, and was impressed by its in-game benchmark, showcasing complex building structure with plenty of trees and structures where aliasing becomes important. The in-game benchmark is an on-rails experience through the scenery, covering both indoor and outdoor scenes – it ends up being very CPU limited in the way it is designed. We have taken an offline version of Chernobylite to use in our tests, and we are testing the following settings combinations:
- 360p Low, 1440p Low, 4K Low, 1080p Max
We do as many runs within 10 minutes per resolution/setting combination, and then take averages.
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 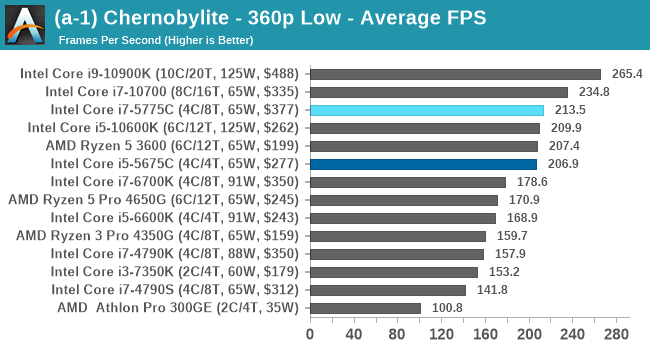 |
 |
 |
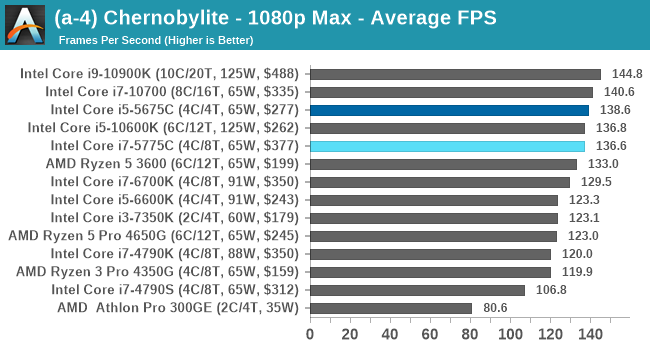 |
The Broadwell CPUs remain high performers here as the frame rates get cranked up, with the Broadwell Core i7+i5 even matching the latest Comet Lake Core i5, even at 1080p Max settings.
For our Integrated Tests, we run the first and last combination of settings.
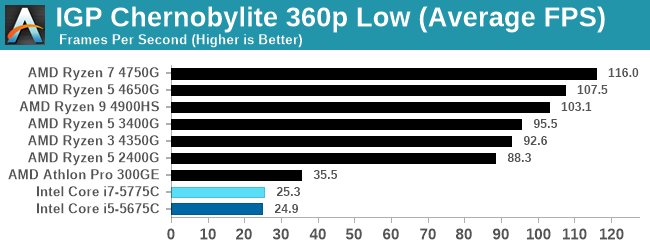
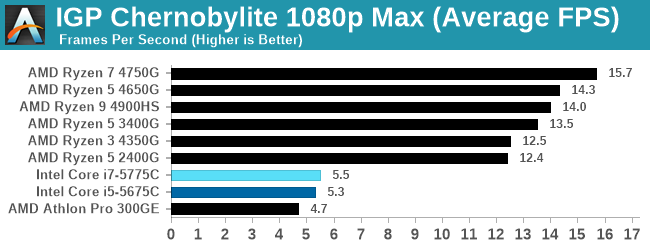
Integrated graphics shows how far AMD's basic options are ahead.
Gaming Tests: Civilization 6
Originally penned by Sid Meier and his team, the Civilization series of turn-based strategy games are a cult classic, and many an excuse for an all-nighter trying to get Gandhi to declare war on you due to an integer underflow. Truth be told I never actually played the first version, but I have played every edition from the second to the sixth, including the fourth as voiced by the late Leonard Nimoy, and it a game that is easy to pick up, but hard to master.
Benchmarking Civilization has always been somewhat of an oxymoron – for a turn based strategy game, the frame rate is not necessarily the important thing here and even in the right mood, something as low as 5 frames per second can be enough. With Civilization 6 however, Firaxis went hardcore on visual fidelity, trying to pull you into the game. As a result, Civilization can taxing on graphics and CPUs as we crank up the details, especially in DirectX 12.
For this benchmark, we are using the following settings:
- 480p Low, 1440p Low, 4K Low, 1080p Max
For automation, Firaxis supports the in-game automated benchmark from the command line, and output a results file with frame times. We do as many runs within 10 minutes per resolution/setting combination, and then take averages and percentiles.
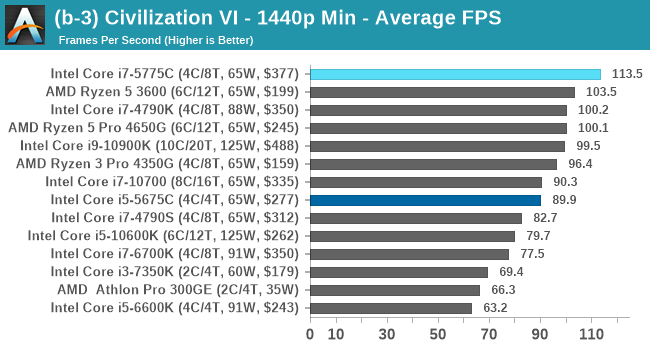
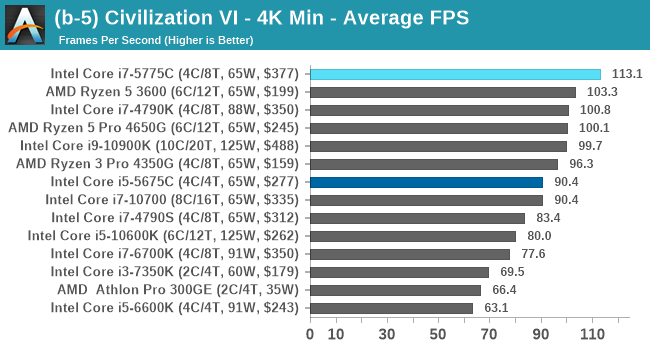
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 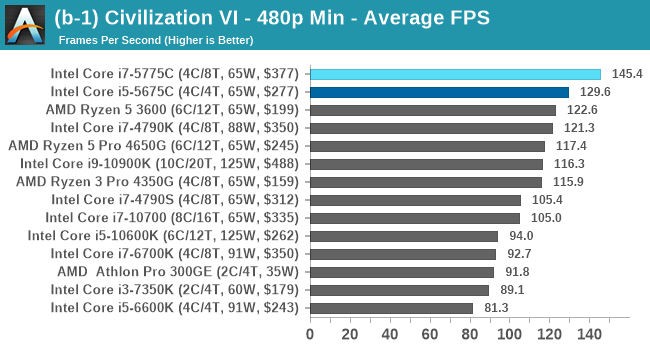 |
 |
 |
 |
| 95th Percentile | 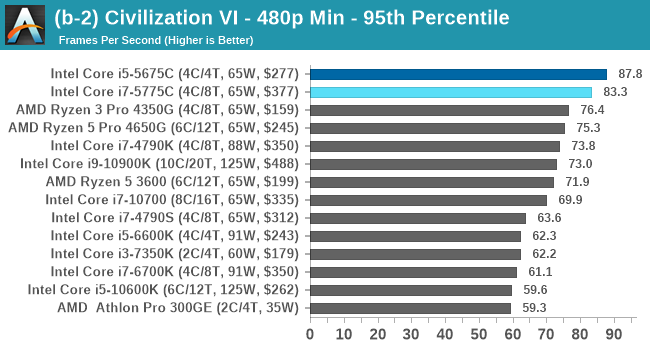 |
 |
 |
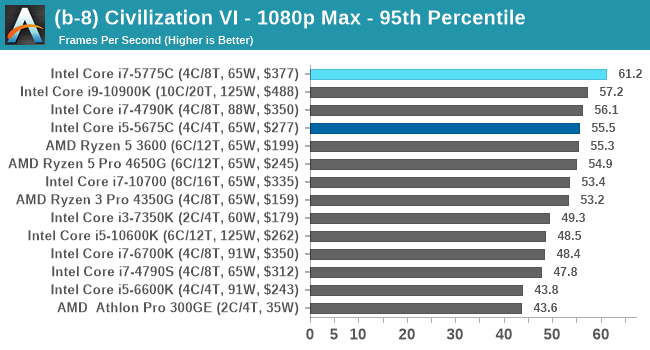 |
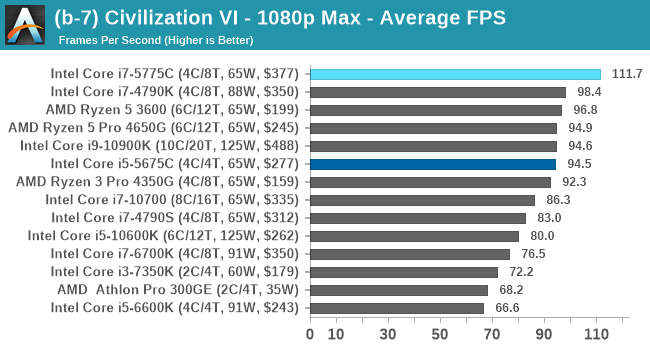
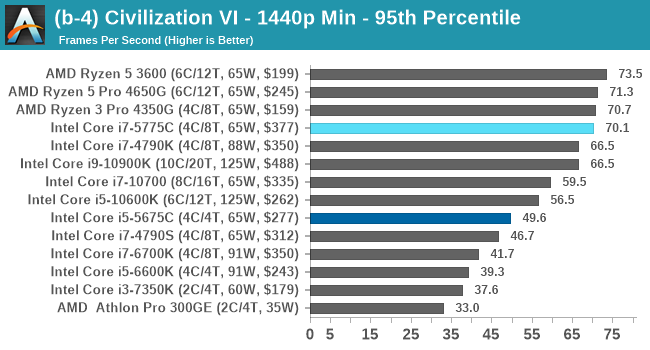
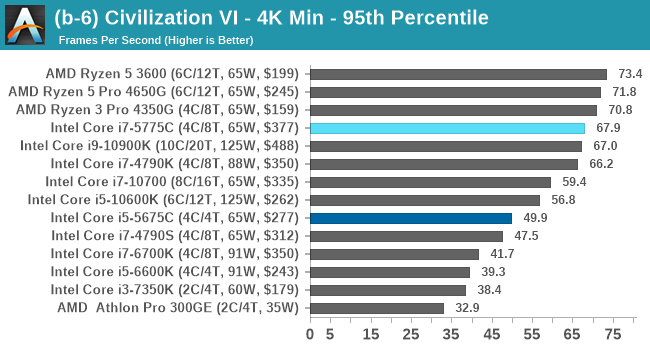
Civ 6 has always been a fan of fast CPU cores and low latency, so perhaps it isn't much of a surprise to see the Core i7 here beat out the latest processors. The Core i7 seems to generate a commanding lead, whereas those behind it seem to fall into a category around 94-96 FPS at 1080p Max settings.
For our Integrated Tests, we run the first and last combination of settings.
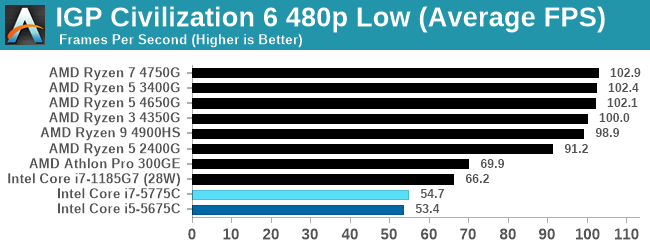
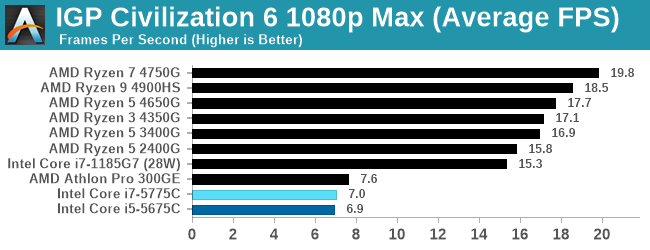
When we use the integrated graphics, Broadwell isn't particularly playable here.
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: Deus Ex Mankind Divided
Deus Ex is a franchise with a wide level of popularity. Despite the Deus Ex: Mankind Divided (DEMD) version being released in 2016, it has often been heralded as a game that taxes the CPU. It uses the Dawn Engine to create a very complex first-person action game with science-fiction based weapons and interfaces. The game combines first-person, stealth, and role-playing elements, with the game set in Prague, dealing with themes of transhumanism, conspiracy theories, and a cyberpunk future. The game allows the player to select their own path (stealth, gun-toting maniac) and offers multiple solutions to its puzzles.

DEMD has an in-game benchmark, an on-rails look around an environment showcasing some of the game’s most stunning effects, such as lighting, texturing, and others. Even in 2020, it’s still an impressive graphical showcase when everything is jumped up to the max. For this title, we are testing the following resolutions:
- 600p Low, 1440p Low, 4K Low, 1080p Max
The benchmark runs for about 90 seconds. We do as many runs within 10 minutes per resolution/setting combination, and then take averages and percentiles.
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 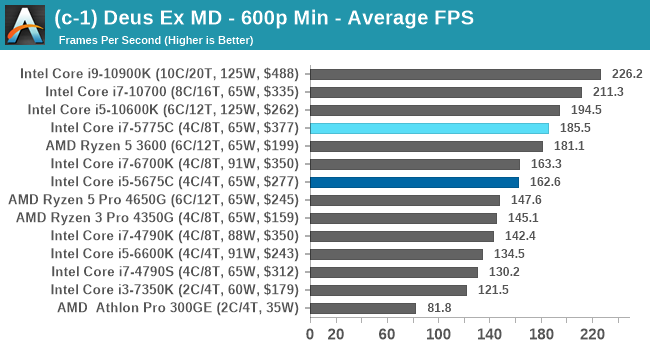 |
 |
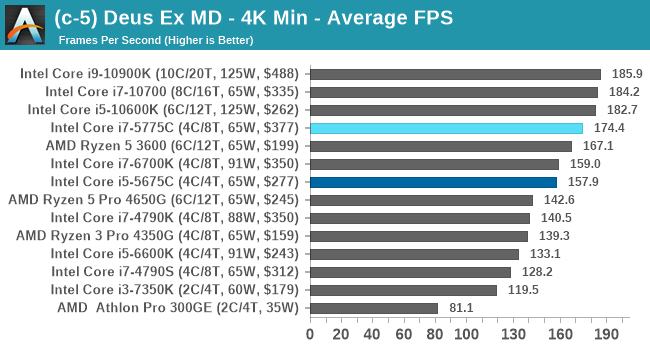 |
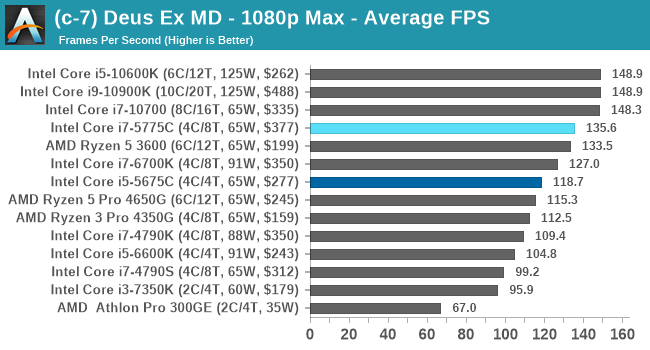 |
| 95th Percentile | 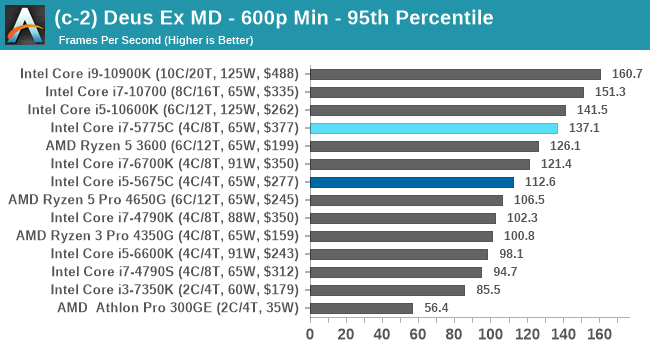 |
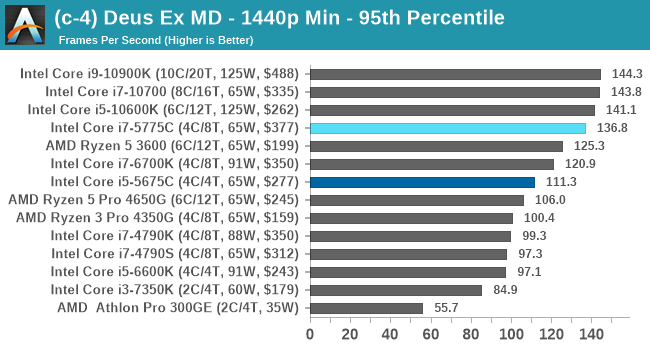 |
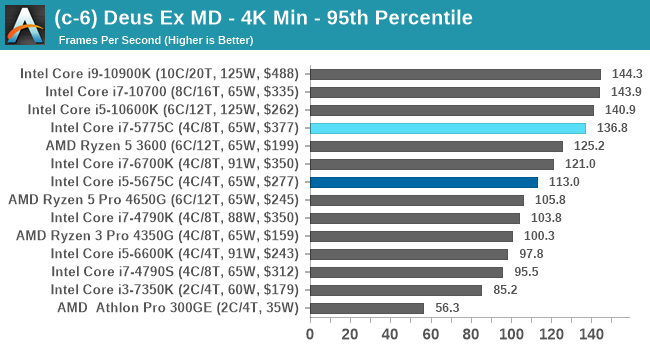 |
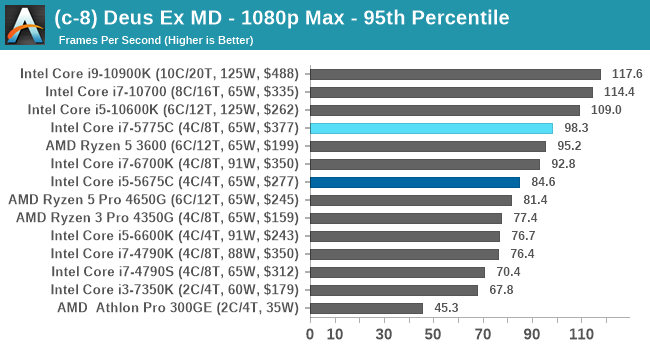 |
Deus Ex:MD is seen more as a CPU benchmark, and the results here are very consistent - the Core i7 Broadwell sits just behind the Comet Lake Core i5 in all settings combinations.
For our Integrated Tests, we run the first and last combination of settings.
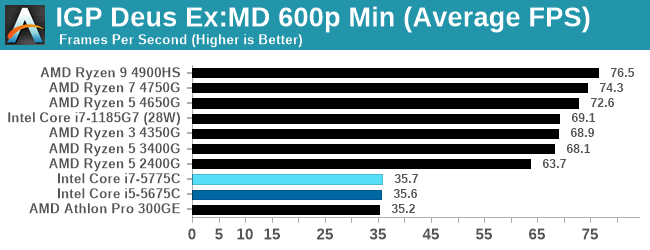
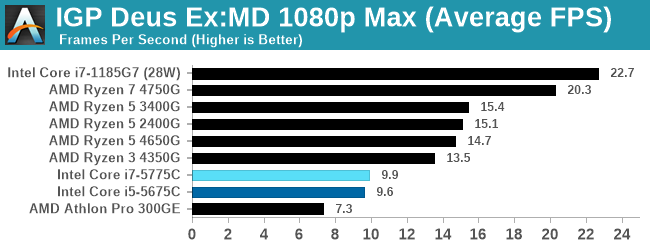
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: Final Fantasy XIV
Despite being one number less than Final Fantasy 15, because FF14 is a massively-multiplayer online title, there are always yearly update packages which give the opportunity for graphical updates too. In 2019, FFXIV launched its Shadowbringers expansion, and an official standalone benchmark was released at the same time for users to understand what level of performance they could expect. Much like the FF15 benchmark we’ve been using for a while, this test is a long 7-minute scene of simulated gameplay within the title. There are a number of interesting graphical features, and it certainly looks more like a 2019 title than a 2010 release, which is when FF14 first came out.
With this being a standalone benchmark, we do not have to worry about updates, and the idea for these sort of tests for end-users is to keep the code base consistent. For our testing suite, we are using the following settings:
- 768p Minimum, 1440p Minimum, 4K Minimum, 1080p Maximum
As with the other benchmarks, we do as many runs until 10 minutes per resolution/setting combination has passed, and then take averages. Realistically, because of the length of this test, this equates to two runs per setting.
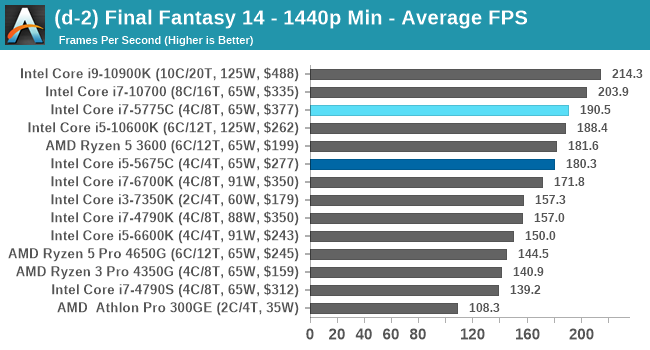
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 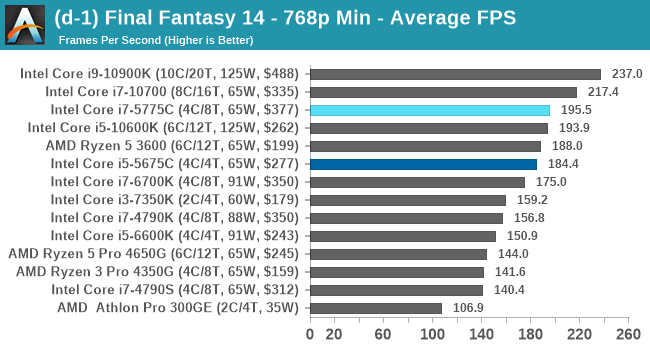 |
 |
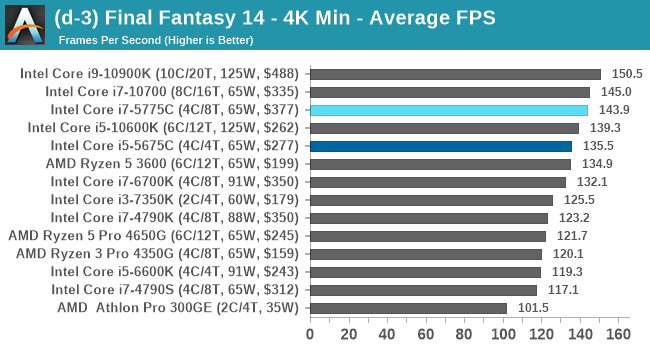 |
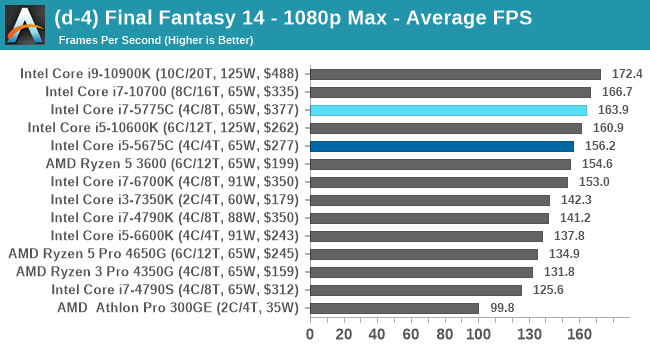 |
Final Fantasy 14 seems to like good memory latency as well, with the Core i7 and Core i5 Broadwell parts scoring high here. Through all the settings runs, the CPU stack remains consistent in the differences.
For our Integrated Tests, we run the first and last combination of settings.
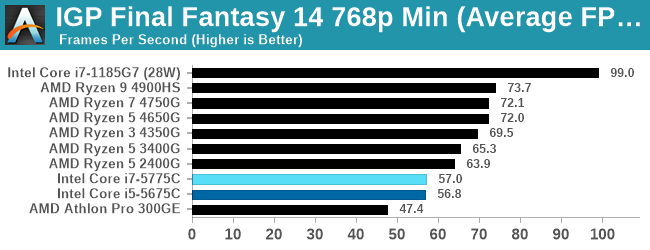
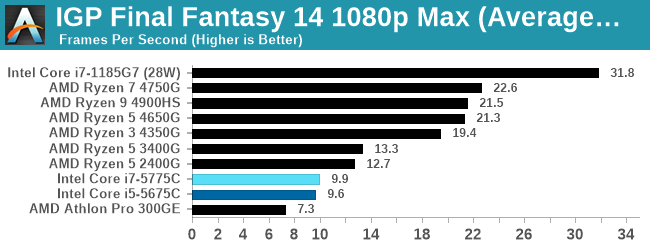
768p Minimum seems playable enough. The Broadwell parts are just nipping on the heels of AMD's Renoir.
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: Final Fantasy XV
Upon arriving to PC, Final Fantasy XV: Windows Edition was given a graphical overhaul as it was ported over from console. As a fantasy RPG with a long history, the fruits of Square-Enix’s successful partnership with NVIDIA are on display. The game uses the internal Luminous Engine, and as with other Final Fantasy games, pushes the imagination of what we can do with the hardware underneath us. To that end, FFXV was one of the first games to promote the use of ‘video game landscape photography’, due in part to the extensive detail even at long range but also with the integration of NVIDIA’s Ansel software, that allowed for super-resolution imagery and post-processing effects to be applied.

In preparation for the launch of the game, Square Enix opted to release a standalone benchmark. Using the Final Fantasy XV standalone benchmark gives us a lengthy standardized sequence to record, although it should be noted that its heavy use of NVIDIA technology means that the Maximum setting has problems - it renders items off screen. To get around this, we use the standard preset which does not have these issues. We use the following settings:
- 720p Standard, 1080p Standard, 4K Standard, 8K Standard
For automation, the title accepts command line inputs for both resolution and settings, and then auto-quits when finished. As with the other benchmarks, we do as many runs until 10 minutes per resolution/setting combination has passed, and then take averages. Realistically, because of the length of this test, this equates to two runs per setting.

| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 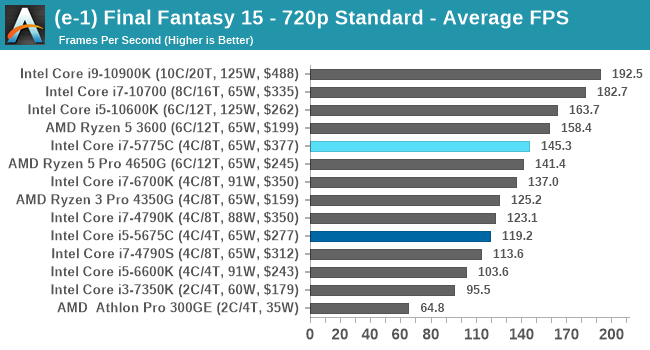 |
 |
 |
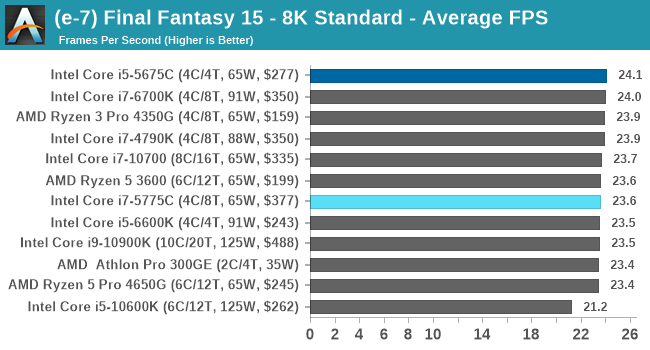 |
| 95th Percentile | 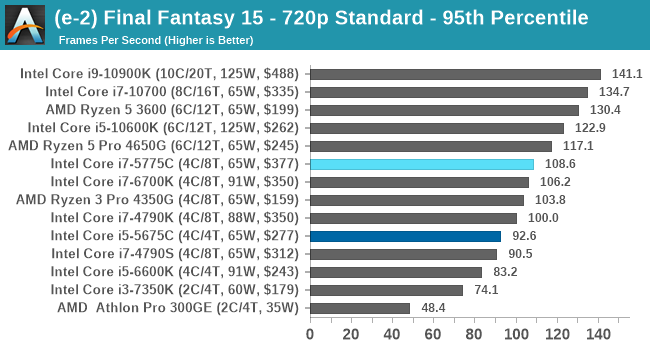 |
 |
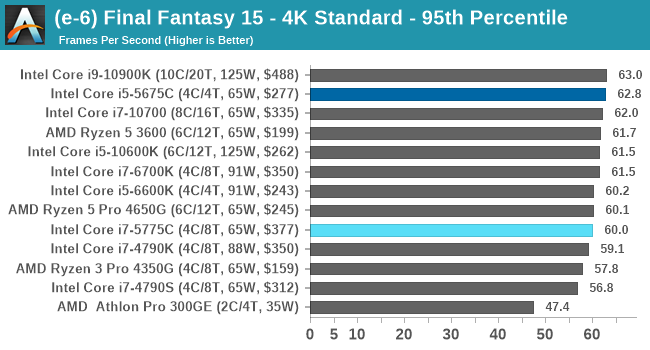 |
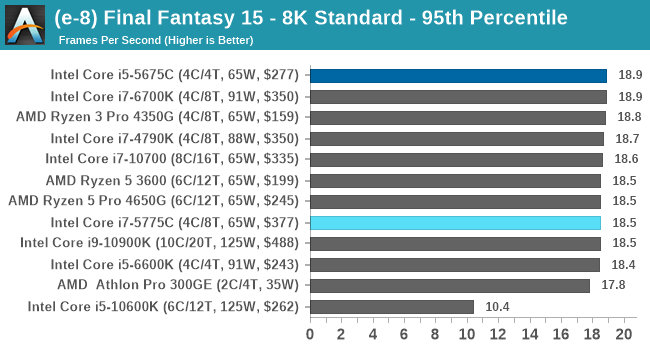 |
In the first two resolution/settings combinations, the Core i7 and Core i5 are clearly high up, with the i7 beating AMD's Ryzen 3 Renoir CPU. In GPU limited tests, they match the rest of the pack.
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: World of Tanks
Albeit different to most of the other commonly played MMO or massively multiplayer online games, World of Tanks is set in the mid-20th century and allows players to take control of a range of military based armored vehicles. World of Tanks (WoT) is developed and published by Wargaming who are based in Belarus, with the game’s soundtrack being primarily composed by Belarusian composer Sergey Khmelevsky. The game offers multiple entry points including a free-to-play element as well as allowing players to pay a fee to open up more features. One of the most interesting things about this tank based MMO is that it achieved eSports status when it debuted at the World Cyber Games back in 2012.

World of Tanks enCore is a demo application for its new graphics engine penned by the Wargaming development team. Over time the new core engine has been implemented into the full game upgrading the games visuals with key elements such as improved water, flora, shadows, lighting as well as other objects such as buildings. The World of Tanks enCore demo app not only offers up insight into the impending game engine changes, but allows users to check system performance to see if the new engine runs optimally on their system. There is technically a Ray Tracing version of the enCore benchmark now available, however because it can’t be deployed standalone without the installer, we decided against using it. If that gets fixed, then we can look into it.
The benchmark tool comes with a number of presets:
- 768p Minimum, 1080p Standard, 1080p Max, 4K Max (not a preset)
The odd one out is the 4K Max preset, because the benchmark doesn’t automatically have a 4K option – to get this we edit the acceptable resolutions ini file, and then we can select 4K. The benchmark outputs its own results file, with frame times, making it very easy to parse the data needed for average and percentiles.

| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 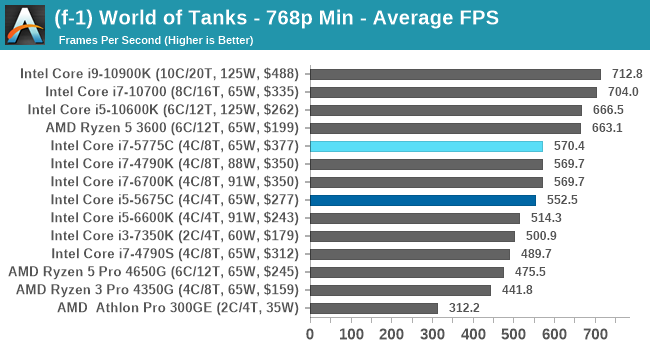 |
 |
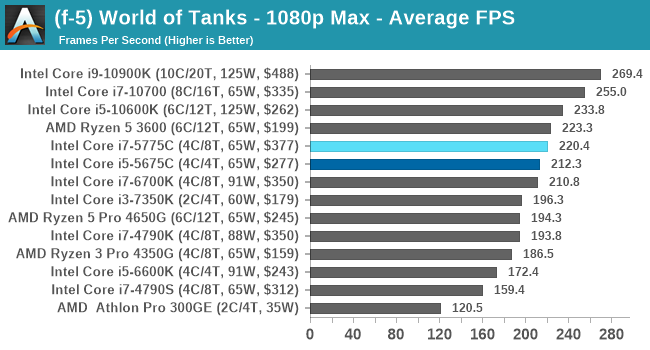 |
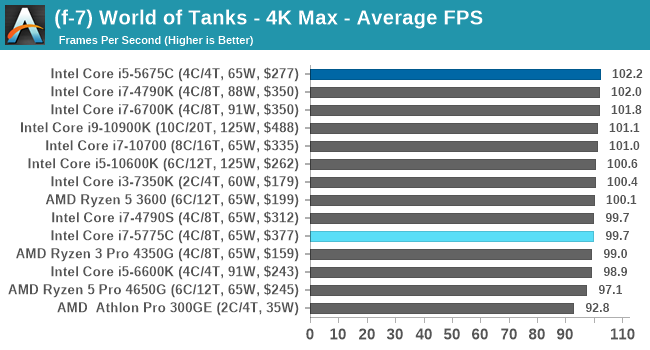 |
| 95th Percentile | 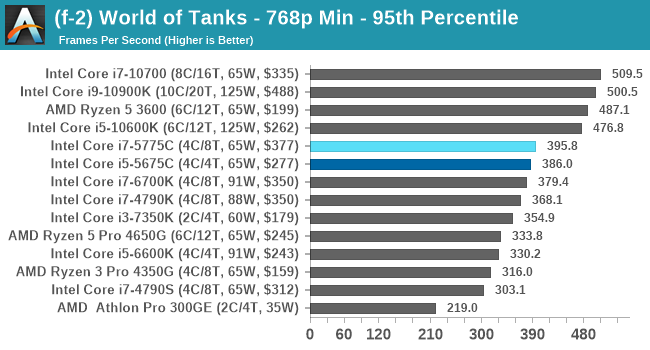 |
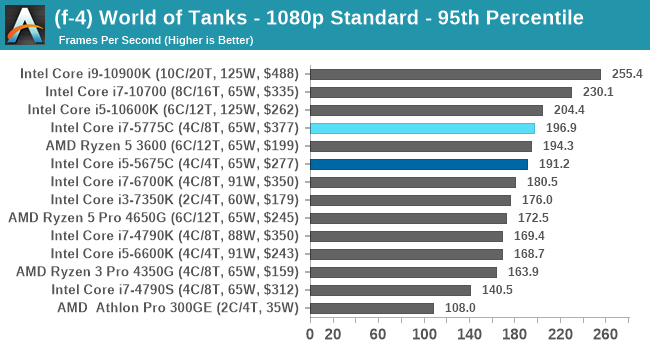 |
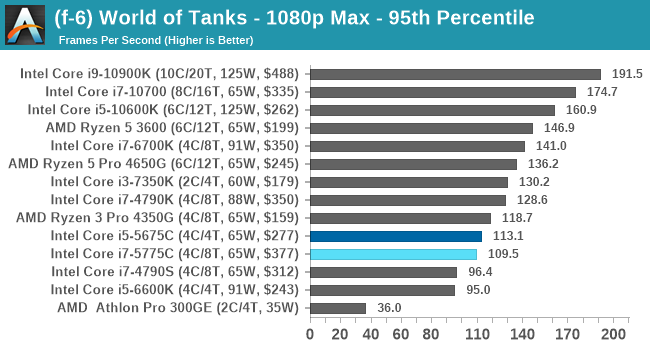 |
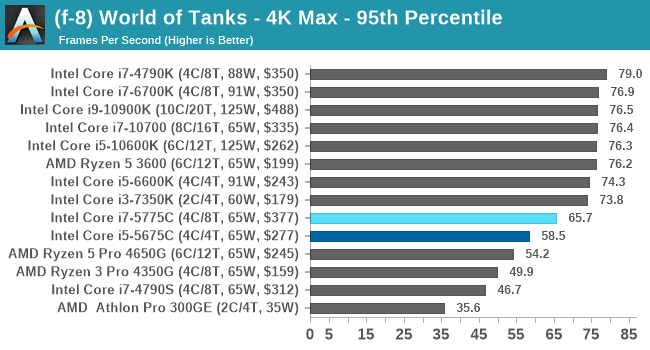 |
WoT always appears to be a good test of CPU gaming, however only in the lowest resolutions are the Broadwell parts competitive. As we crank up the settings, the minimum frame rates are more indicative of Broadwell positioning.
For our Integrated Tests, we run the first settings.
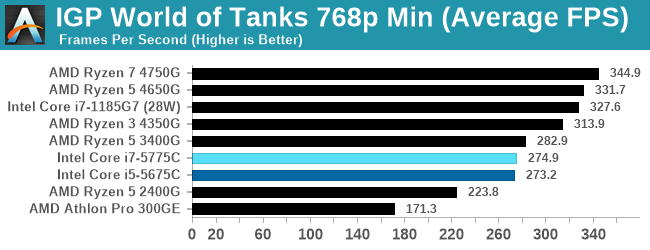
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: Borderlands 3
As a big Borderlands fan, having to sit and wait six months for the EPIC Store exclusive to expire before we saw it on Steam felt like a long time to wait. The fourth title of the franchise, if you exclude the TellTale style-games, BL3 expands the universe beyond Pandora and its orbit, with the set of heroes (plus those from previous games) now cruising the galaxy looking for vaults and the treasures within. Popular Characters like Tiny Tina, Claptrap, Lilith, Dr. Zed, Zer0, Tannis, and others all make appearances as the game continues its cel-shaded design but with the graphical fidelity turned up. Borderlands 1 gave me my first ever taste of proper in-game second order PhysX, and it’s a high standard that continues to this day.

BL3 works best with online access, so it is filed under our online games section. BL3 is also one of our biggest downloads, requiring 100+ GB. As BL3 supports resolution scaling, we are using the following settings:
- 360p Very Low, 1440p Very Low, 4K Very Low, 1080p Badass
BL3 has its own in-game benchmark, which recreates a set of on-rails scenes with a variety of activity going on in each, such as shootouts, explosions, and wildlife. The benchmark outputs its own results files, including frame times, which can be parsed for our averages/percentile data.
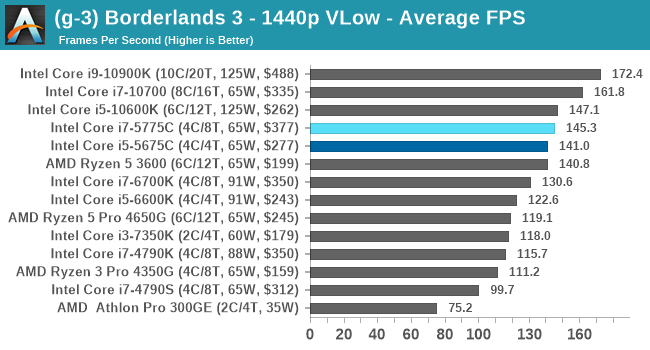
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 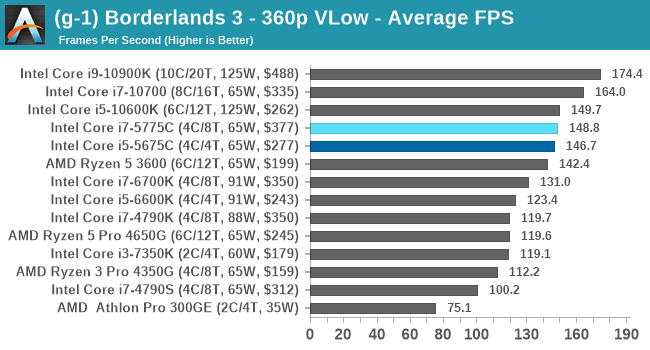 |
 |
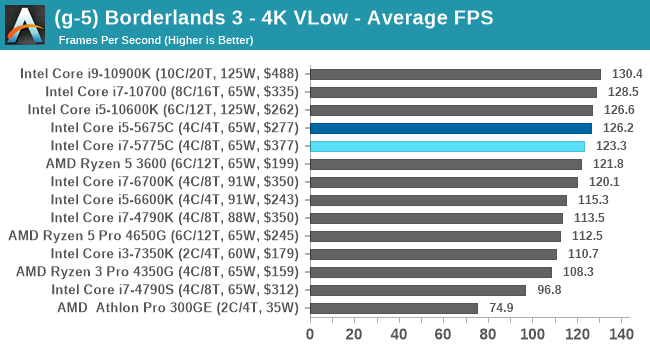 |
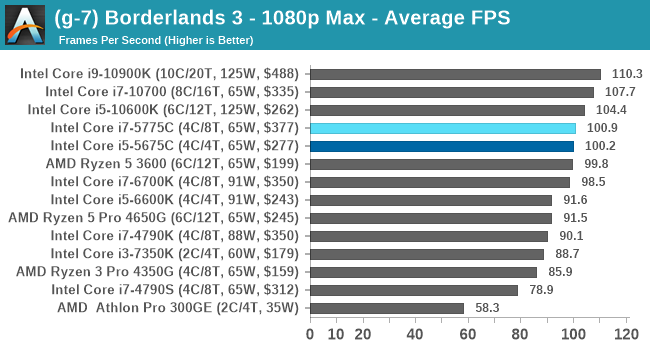 |
| 95th Percentile | 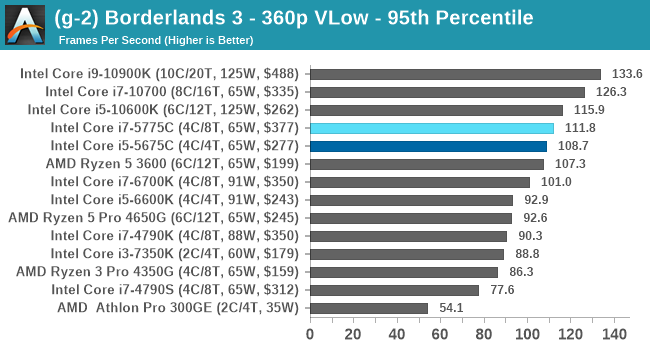 |
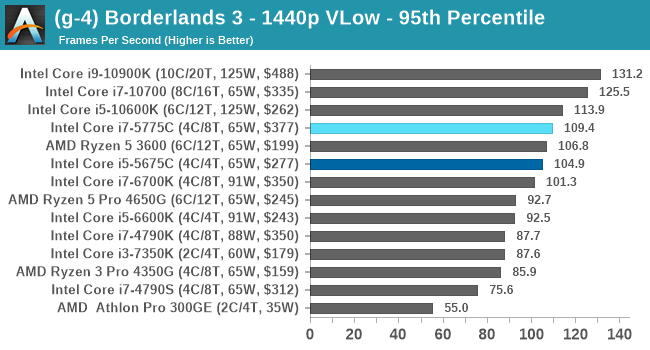 |
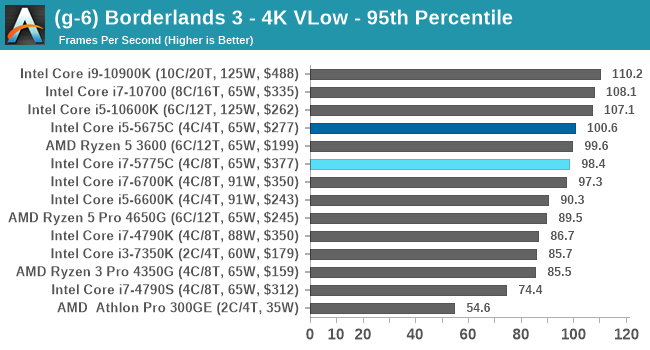 |
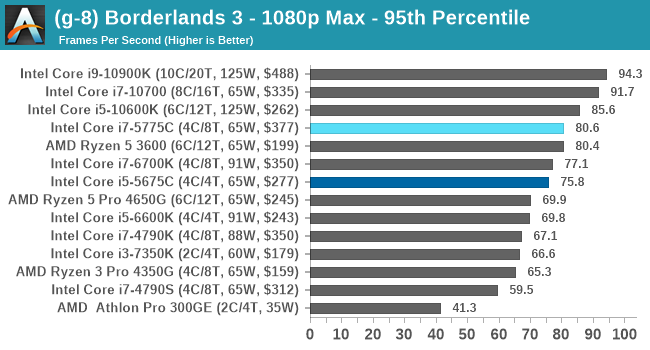 |
Another consistent test, with the Core i7 and Core i5 sitting just behind Intel's Comet Lake i5.
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: F1 2019
The F1 racing games from Codemasters have been popular benchmarks in the tech community, mostly for ease-of-use and that they seem to take advantage of any area of a machine that might be better than another. The 2019 edition of the game features all 21 circuits on the calendar for that year, and includes a range of retro models and DLC focusing on the careers of Alain Prost and Ayrton Senna. Built on the EGO Engine 3.0, the game has been criticized similarly to most annual sports games, by not offering enough season-to-season graphical fidelity updates to make investing in the latest title worth it, however the 2019 edition revamps up the Career mode, with features such as in-season driver swaps coming into the mix. The quality of the graphics this time around is also superb, even at 4K low or 1080p Ultra.

For our test, we put Alex Albon in the Red Bull in position #20, for a dry two-lap race around Austin. We test at the following settings:
- 768p Ultra Low, 1440p Ultra Low, 4K Ultra Low, 1080p Ultra
In terms of automation, F1 2019 has an in-game benchmark that can be called from the command line, and the output file has frame times. We repeat each resolution setting for a minimum of 10 minutes, taking the averages and percentiles.
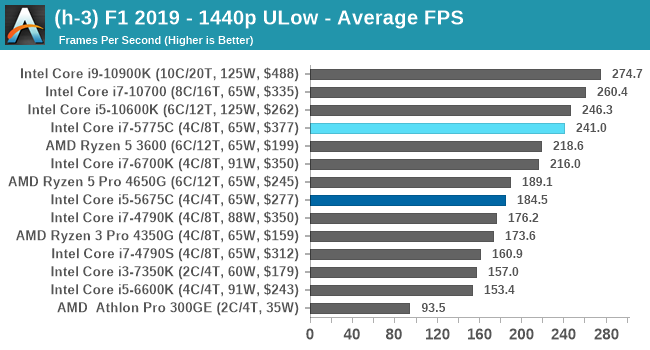
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 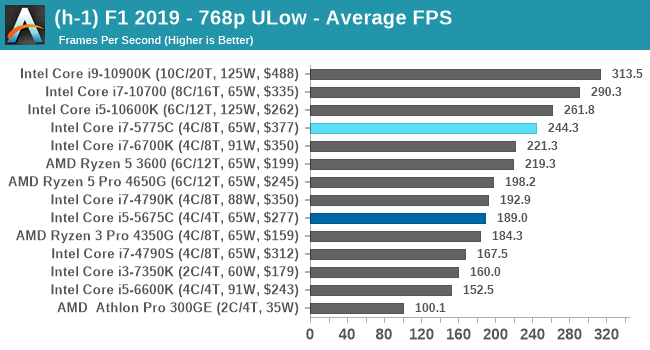 |
 |
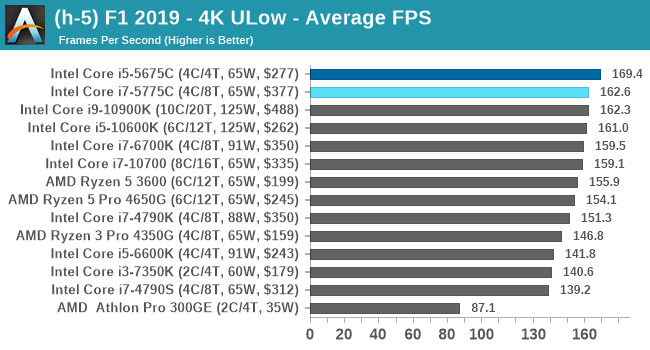 |
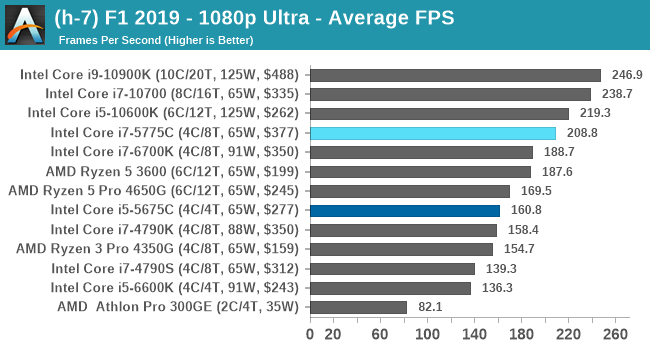 |
| 95th Percentile | 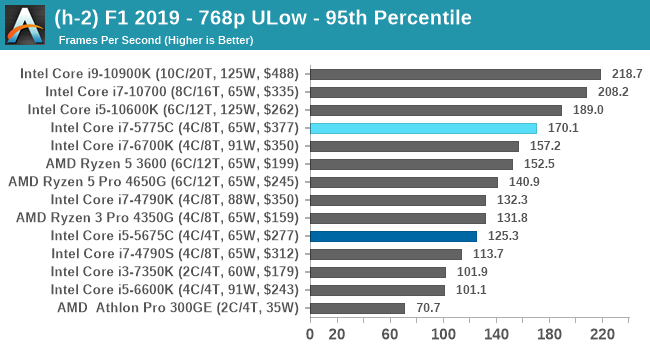 |
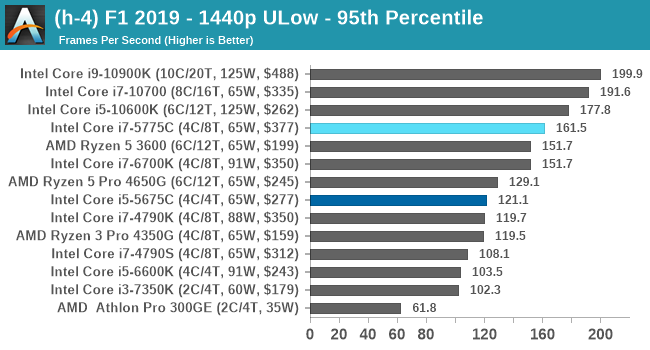 |
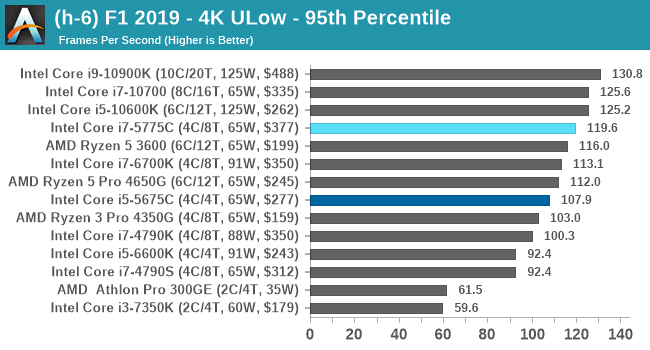 |
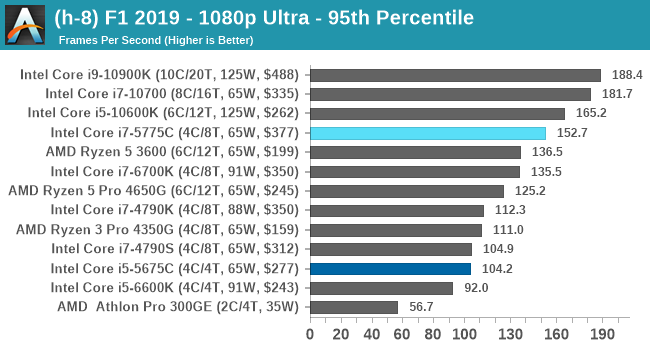 |
At our 4K Ultra-Low settings, the Broadwell parts seem to rule the roost at average frame rates. For other settings, we again see the BDW i7 just behind the CML i5.
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: Far Cry 5
The fifth title in Ubisoft's Far Cry series lands us right into the unwelcoming arms of an armed militant cult in Montana, one of the many middles-of-nowhere in the United States. With a charismatic and enigmatic adversary, gorgeous landscapes of the northwestern American flavor, and lots of violence, it is classic Far Cry fare. Graphically intensive in an open-world environment, the game mixes in action and exploration with a lot of configurability.

Unfortunately, the game doesn’t like us changing the resolution in the results file when using certain monitors, resorting to 1080p but keeping the quality settings. But resolution scaling does work, so we decided to fix the resolution at 1080p and use a variety of different scaling factors to give the following:
- 720p Low, 1440p Low, 4K Low, 1440p Max.
Far Cry 5 outputs a results file here, but that the file is a HTML file, which showcases a graph of the FPS detected. At no point in the HTML file does it contain the frame times for each frame, but it does show the frames per second, as a value once per second in the graph. The graph in HTML form is a series of (x,y) co-ordinates scaled to the min/max of the graph, rather than the raw (second, FPS) data, and so using regex I carefully tease out the values of the graph, convert them into a (second, FPS) format, and take our values of averages and percentiles that way.
If anyone from Ubisoft wants to chat about building a benchmark platform that would not only help me but also every other member of the tech press build our benchmark testing platform to help our readers decide what is the best hardware to use on your games, please reach out to ian@anandtech.com. Some of the suggestions I want to give you will take less than half a day and it’s easily free advertising to use the benchmark over the next couple of years (or more).
As with the other gaming tests, we run each resolution/setting combination for a minimum of 10 minutes and take the relevant frame data for averages and percentiles.
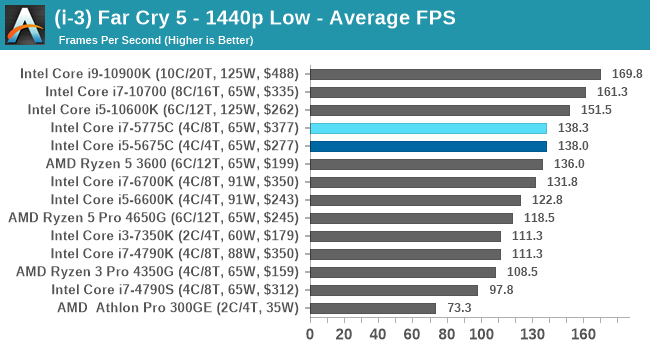
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS |  |
 |
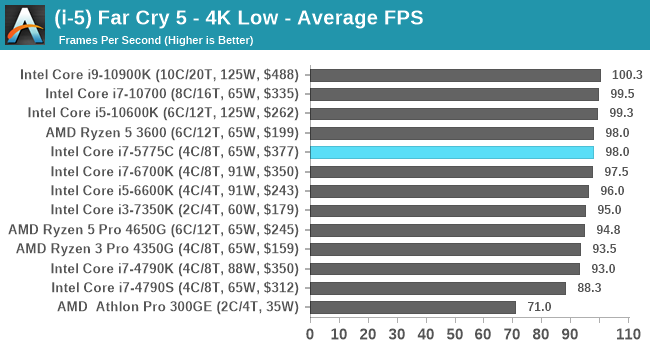 |
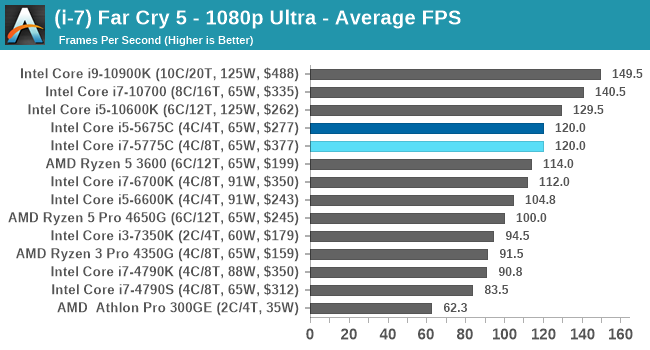 |
| 95th Percentile | 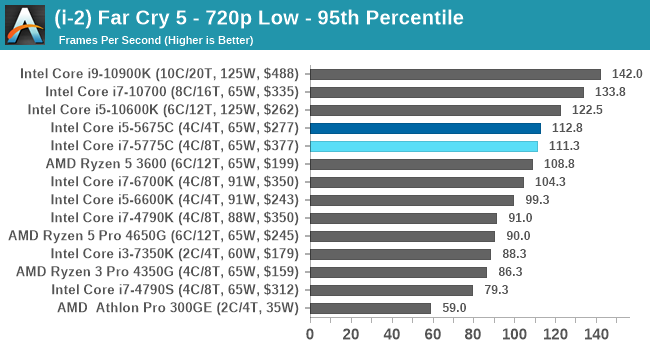 |
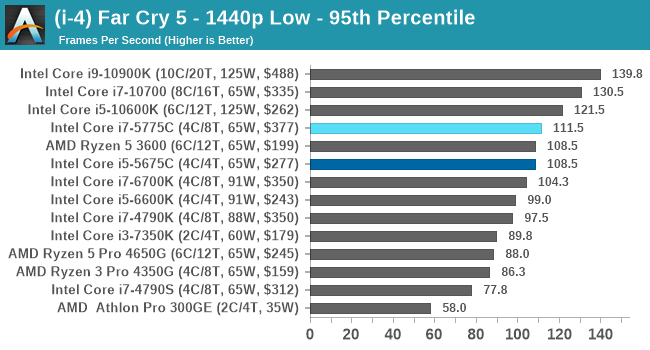 |
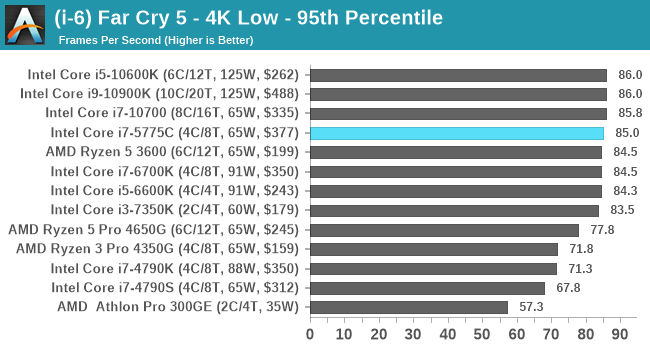 |
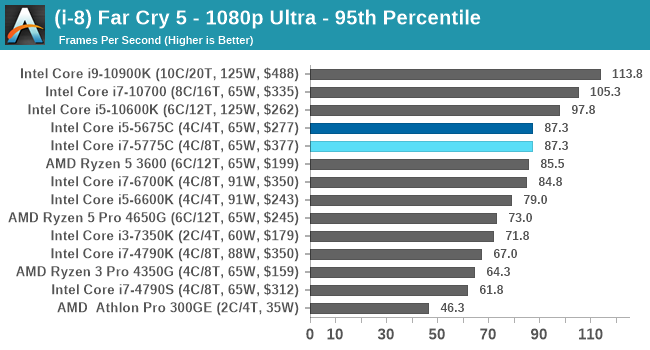 |
For our Integrated Tests, we run the first settings.
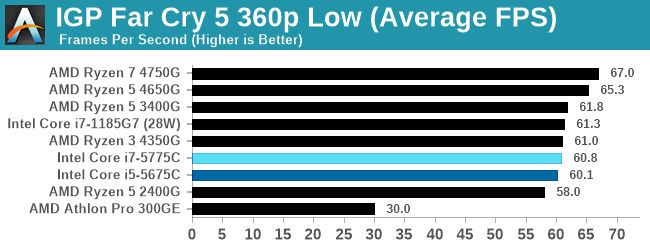
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: Gears Tactics
Remembering the original Gears of War brings back a number of memories – some good, and some involving online gameplay. The latest iteration of the franchise was launched as I was putting this benchmark suite together, and Gears Tactics is a high-fidelity turn-based strategy game with an extensive single player mode. As with a lot of turn-based games, there is ample opportunity to crank up the visual effects, and here the developers have put a lot of effort into creating effects, a number of which seem to be CPU limited.
Gears Tactics has an in-game benchmark, roughly 2.5 minutes of AI gameplay starting from the same position but using a random seed for actions. Much like the racing games, this usually leads to some variation in the run-to-run data, so for this benchmark we are taking the geometric mean of the results. One of the biggest things that Gears Tactics can do is on the resolution scaling, supporting 8K, and so we are testing the following settings:
- 720p Low, 4K Low, 8K Low, 1080p Ultra
For results, the game showcases a mountain of data when the benchmark is finished, such as how much the benchmark was CPU limited and where, however none of that is ever exported into a file we can use. It’s just a screenshot which we have to read manually.
If anyone from the Gears Tactics team wants to chat about building a benchmark platform that would not only help me but also every other member of the tech press build our benchmark testing platform to help our readers decide what is the best hardware to use on your games, please reach out to ian@anandtech.com. Some of the suggestions I want to give you will take less than half a day and it’s easily free advertising to use the benchmark over the next couple of years (or more).
As with the other benchmarks, we do as many runs until 10 minutes per resolution/setting combination has passed. For this benchmark, we manually read each of the screenshots for each quality/setting/run combination. The benchmark does also give 95th percentiles and frame averages, so we can use both of these data points.

| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS |  |
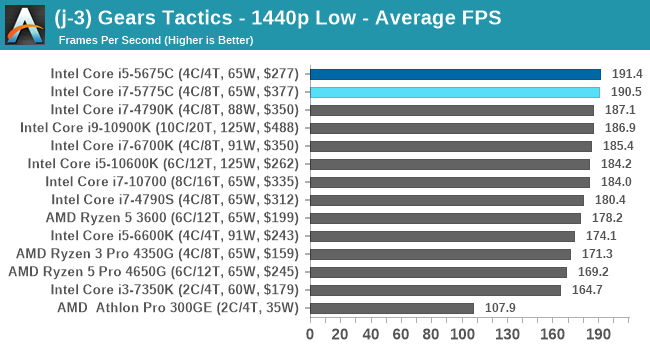 |
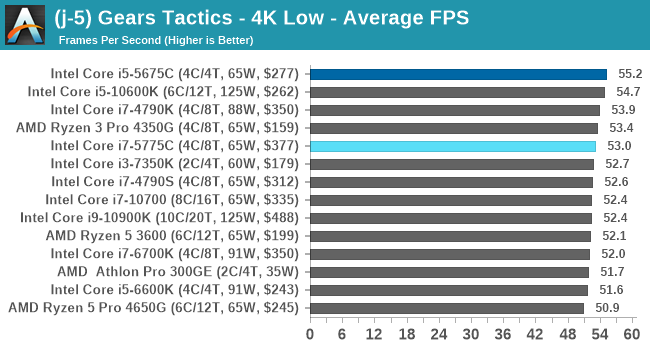 |
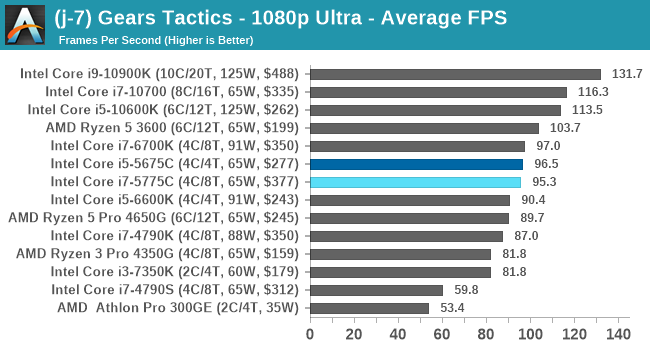 |
| 95th Percentile | 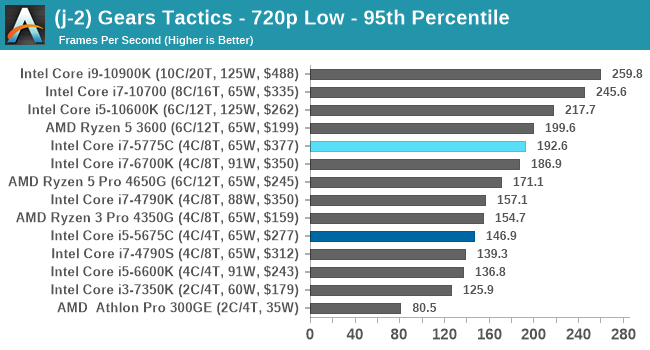 |
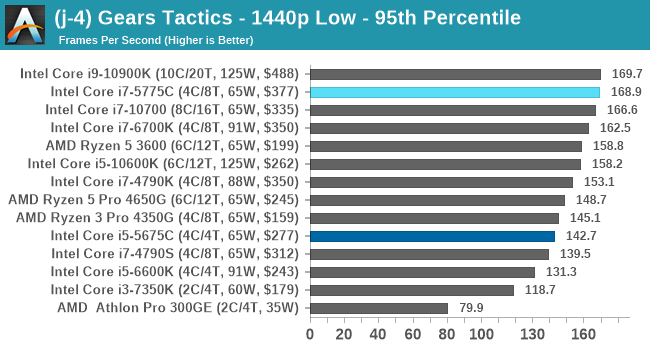 |
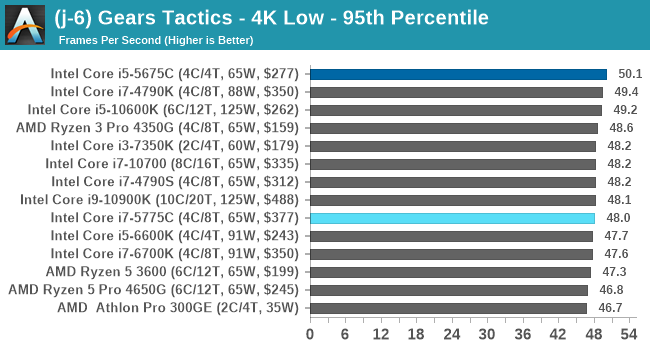 |
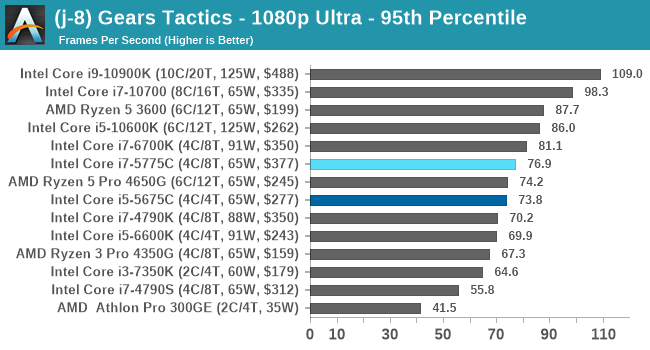 |
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: GTA 5
The highly anticipated iteration of the Grand Theft Auto franchise hit the shelves on April 14th 2015, with both AMD and NVIDIA to help optimize the title. At this point GTA V is super old, but still super useful as a benchmark – it is a complicated test with many features that modern titles today still struggle with. With rumors of a GTA 6 on the horizon, I hope Rockstar make that benchmark as easy to use as this one is.

GTA doesn’t provide graphical presets, but opens up the options to users and extends the boundaries by pushing even the hardest systems to the limit using Rockstar’s Advanced Game Engine under DirectX 11. Whether the user is flying high in the mountains with long draw distances or dealing with assorted trash in the city, when cranked up to maximum it creates stunning visuals but hard work for both the CPU and the GPU.
We are using the following settings:
- 720p Low, 1440p Low, 4K Low, 1080p Max
The in-game benchmark consists of five scenarios: four short panning shots with varying lighting and weather effects, and a fifth action sequence that lasts around 90 seconds. We use only the final part of the benchmark, which combines a flight scene in a jet followed by an inner city drive-by through several intersections followed by ramming a tanker that explodes, causing other cars to explode as well. This is a mix of distance rendering followed by a detailed near-rendering action sequence, and the title thankfully spits out frame time data. The benchmark can also be called from the command line, making it very easy to use.
There is one funny caveat with GTA. If the CPU is too slow, or has too few cores, the benchmark loads, but it doesn’t have enough time to put items in the correct position. As a result, for example when running our single core Sandy Bridge system, the jet ends up stuck at the middle of an intersection causing a traffic jam. Unfortunately this means the benchmark never ends, but still amusing.
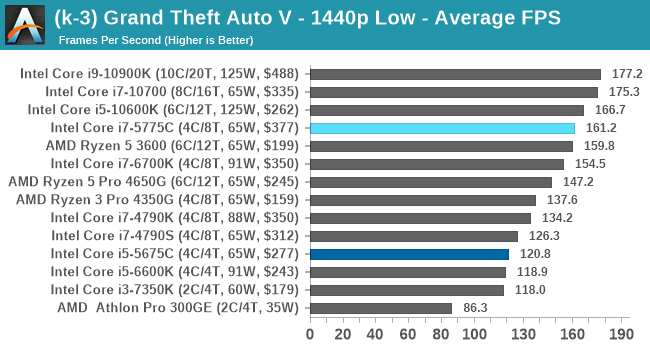
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS |  |
 |
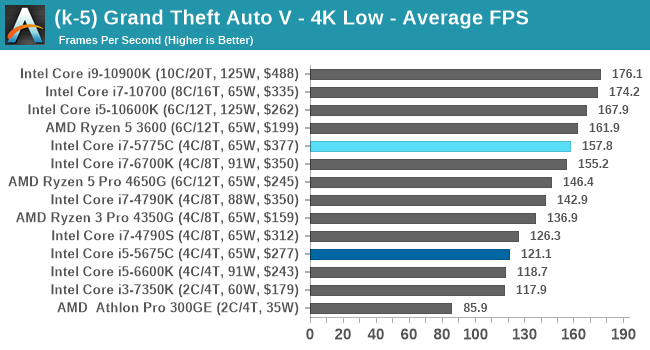 |
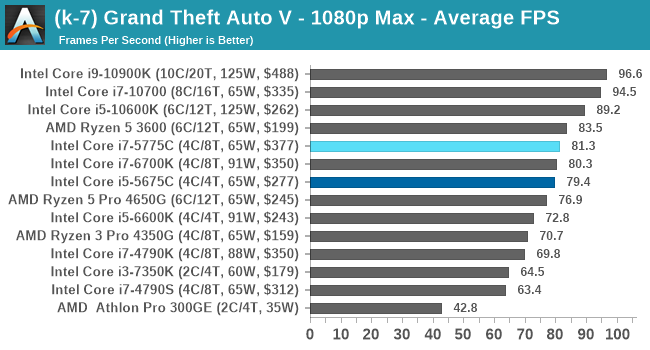 |
| 95th Percentile | 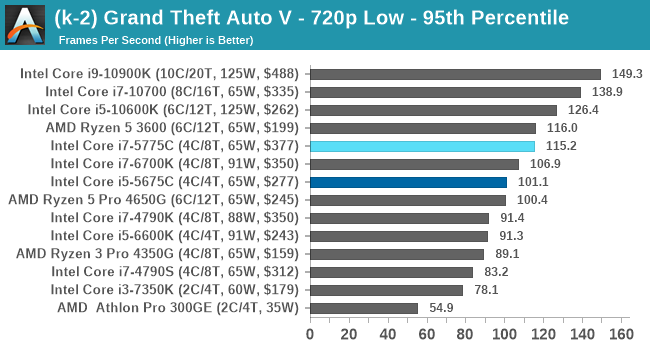 |
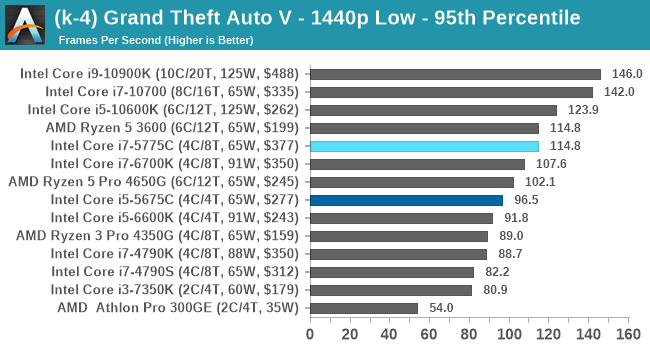 |
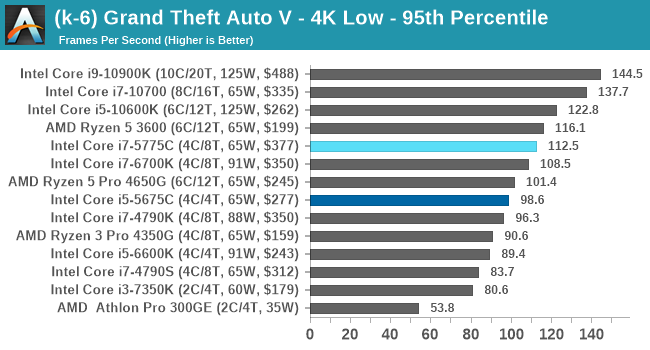 |
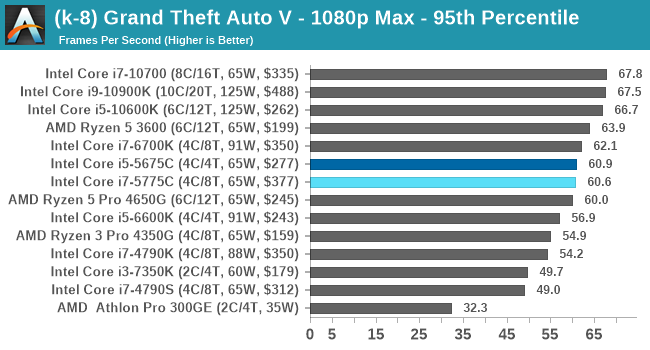 |
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: Red Dead Redemption 2
It’s great to have another Rockstar benchmark in the mix, and the launch of Red Dead Redemption 2 (RDR2) on the PC gives us a chance to do that. Building on the success of the original RDR, the second incarnation came to Steam in December 2019 having been released on consoles first. The PC version takes the open-world cowboy genre into the start of the modern age, with a wide array of impressive graphics and features that are eerily close to reality.

For RDR2, Rockstar kept the same benchmark philosophy as with Grand Theft Auto V, with the benchmark consisting of several cut scenes with different weather and lighting effects, with a final scene focusing on an on-rails environment, only this time with mugging a shop leading to a shootout on horseback before riding over a bridge into the great unknown. Luckily most of the command line options from GTA V are present here, and the game also supports resolution scaling. We have the following tests:
- 384p Minimum, 1440p Minimum, 8K Minimum, 1080p Max
For that 8K setting, I originally thought I had the settings file at 4K and 1.0x scaling, but it was actually set at 2.0x giving that 8K. For the sake of it, I decided to keep the 8K settings.
For our results, we run through each resolution and setting configuration for a minimum of 10 minutes, before averaging and parsing the frame time data.
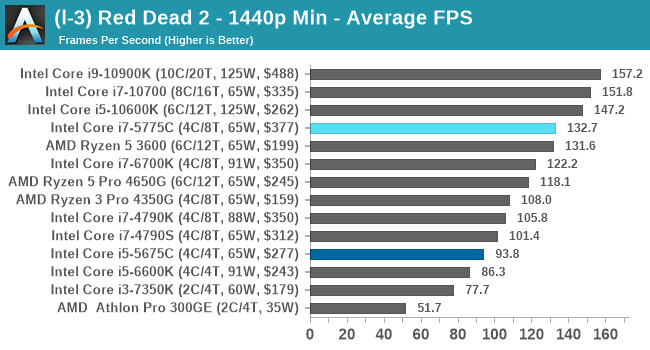
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS | 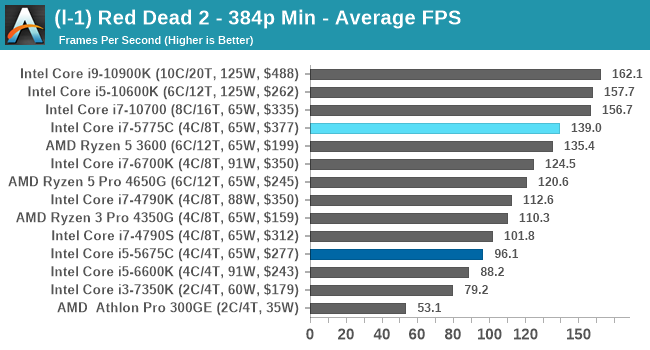 |
 |
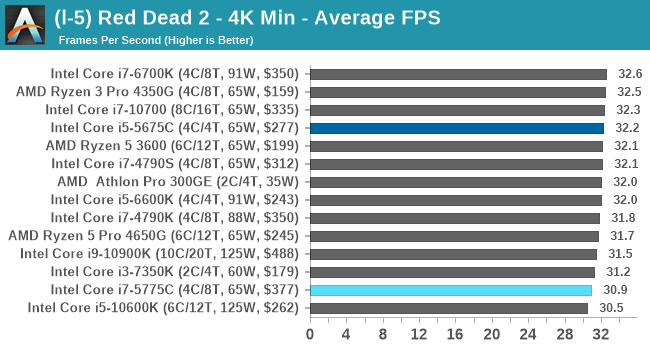 |
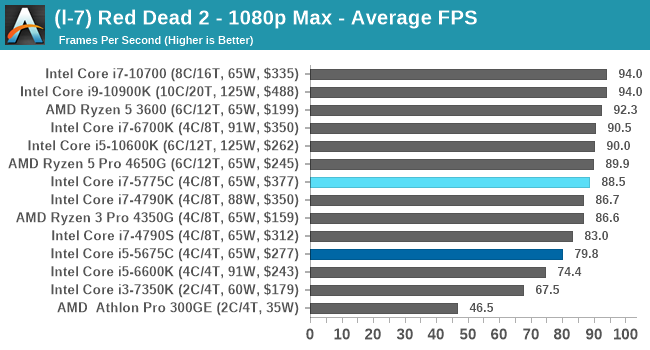 |
| 95th Percentile | 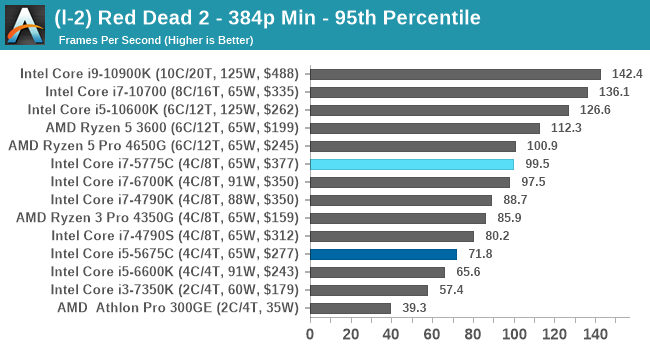 |
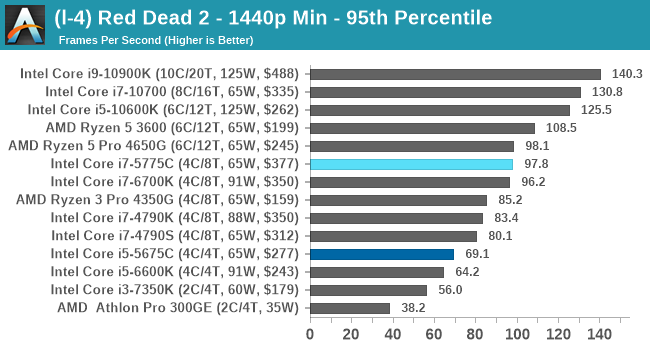 |
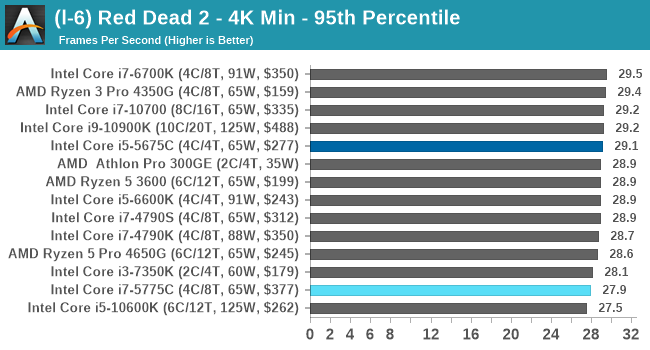 |
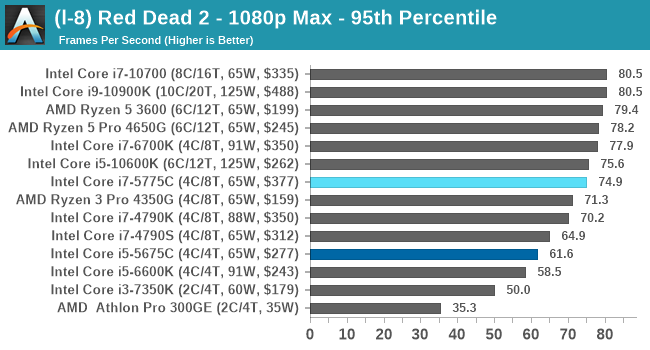 |
All of our benchmark results can also be found in our benchmark engine, Bench.
Gaming Tests: Strange Brigade
Strange Brigade is based in 1903’s Egypt, and follows a story which is very similar to that of the Mummy film franchise. This particular third-person shooter is developed by Rebellion Developments which is more widely known for games such as the Sniper Elite and Alien vs Predator series. The game follows the hunt for Seteki the Witch Queen, who has arose once again and the only ‘troop’ who can ultimately stop her. Gameplay is cooperative centric with a wide variety of different levels and many puzzles which need solving by the British colonial Secret Service agents sent to put an end to her reign of barbaric and brutality.

The game supports both the DirectX 12 and Vulkan APIs and houses its own built-in benchmark as an on-rails experience through the game. For quality, the game offers various options up for customization including textures, anti-aliasing, reflections, draw distance and even allows users to enable or disable motion blur, ambient occlusion and tessellation among others. Strange Brigade supports Vulkan and DX12, and so we test on both.
- 720p Low, 1440p Low, 4K Low, 1080p Ultra
The automation for Strange Brigade is one of the easiest in our suite – the settings and quality can be changed by pre-prepared .ini files, and the benchmark is called via the command line. The output includes all the frame time data.
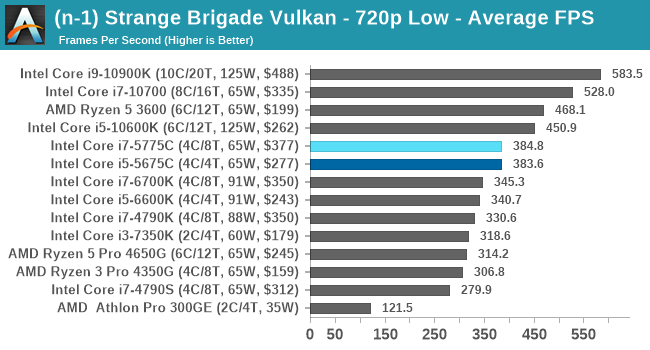
| AnandTech | Low Res Low Qual |
Medium Res Low Qual |
High Res Low Qual |
Medium Res Max Qual |
| Average FPS |  |
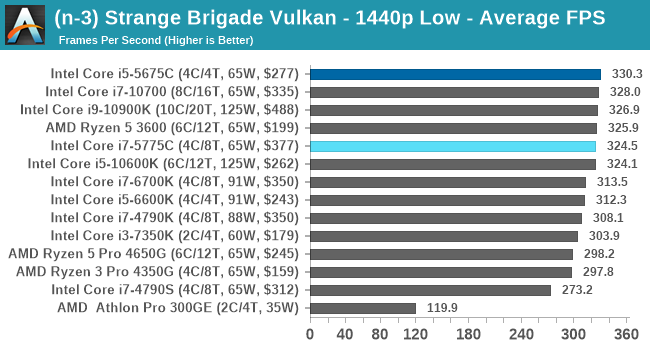 |
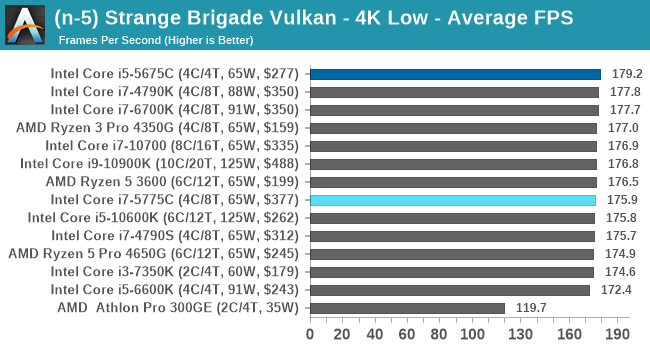 |
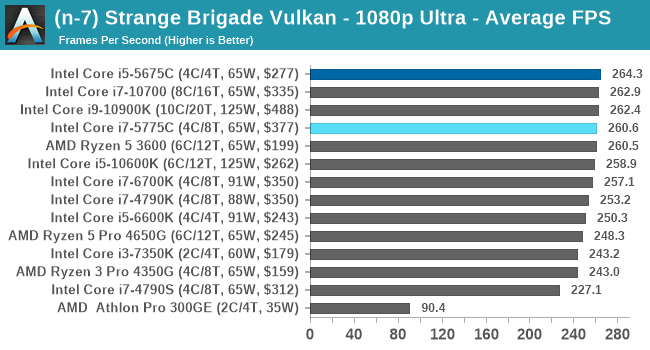 |
| 95th Percentile | 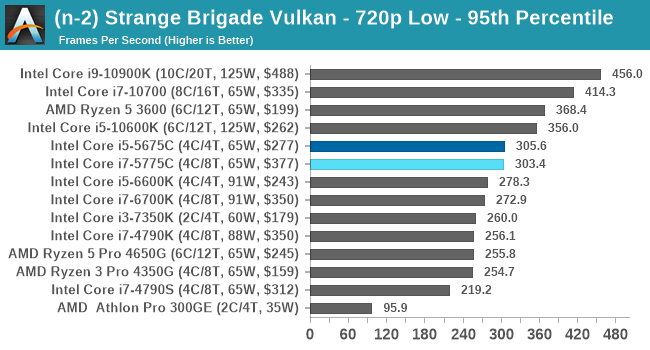 |
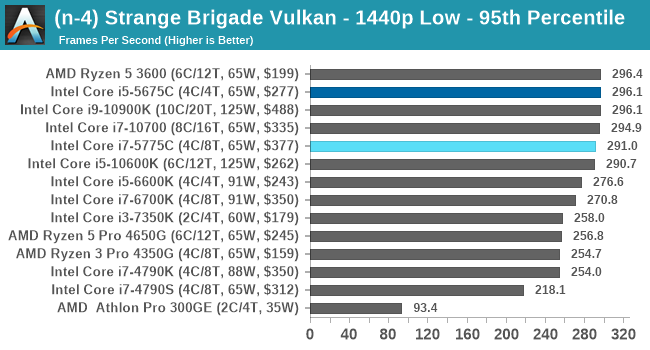 |
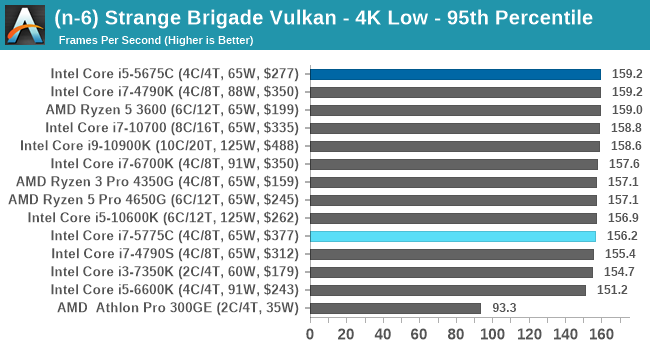 |
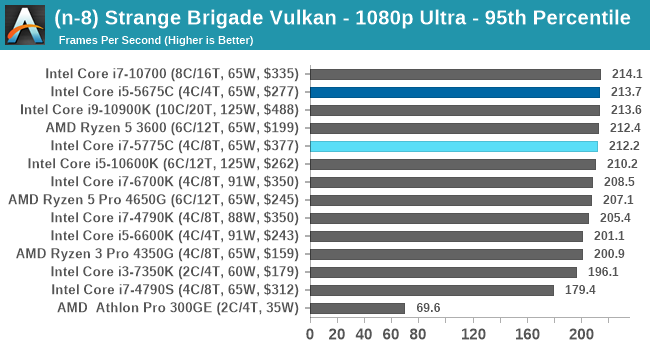 |
All of our benchmark results can also be found in our benchmark engine, Bench.
Broadwell with eDRAM: Still Has Gaming Legs
As we crossover into the 2020s era, we now have more memory bandwidth from DRAM than a processor in 2015. Intel's Broadwell processors were advertised as having 128 megabytes of 'eDRAM', which enabled 50 GiB/s of bidirectional bandwidth at a lower latency of main memory, which ran only at 25.6 GiB/s. Modern processors have access to DDR4-3200, which is 51.2 GiB/s, and future processors are looking at 65 GiB/s or higher.

At this time, it is perhaps poignant to take a step back and understand the beauty of having 128 MiB of dedicated silicon for a singular task.
Intel’s eDRAM enabled Broadwell processors accelerated a significant number of memory bandwidth and memory latency workloads, in particular gaming. What eDRAM has enabled in our testing, even if we bypass the now antiquated CPU performance, is surprisingly good gaming performance. Most of our CPU gaming tests are designed to enable a CPU-limited scenario, which is exactly where Broadwell can play best. Our final CPU gaming test is a 1080p Max scenario where the CPU matters less, but there still appears to be good benefits from having an on-die DRAM and that much lower latency all the way out to 128 MiB.
There have always been questions around exactly what 128 MiB of eDRAM cost Intel to produce and supply to a generation of processors. At launch, Intel priced the eDRAM versions of 14 nm Broadwell processors as +$60 above the non-eDRAM versions of 22 nm Haswell equivalents. There are arguments to say that it cost Intel directly somewhere south of $10 per processor to build and enable, but Intel couldn’t charge that low, based on market segmentation. Remember, that eDRAM was built on a mature 22 nm SoC process at the time.
As we move into an era where AMD is showcasing its new ‘double’ 32 MiB L3 cache on Zen 3 as a key part of their improved gaming performance, we already had 128 MiB of gaming acceleration in 2015. It was enabled through a very specific piece of hardware built into the chip. If we could do it in 2015, why can’t we do it in 2020?

What about HBM-enabled eDRAM for 2021?
Fast forward to 2020, and we now have mature 14 nm and 7 nm processes, as well as a cavalcade of packaging and eDRAM opportunities. We might consider that adding 1-2 GiB of eDRAM to a package could be done with high bandwidth connectivity, using either Intel’s embedded multi-die technology or TSMC’s 3DFabric technology.
If we did that today, it could arguably be just as complex as what it was to add 128 MiB back in 2015. We now have extensive EDA and packaging tools to deal with chiplet designs and multi-die environments.
So consider, at a time where high performance consumer processors are in the realm of $300 up to $500-$800, would customers consider paying +$60 more for a modern high-end processor with 2 gigabytes of intermediate L4 cache? It would extend AMD’s idea of high-performance gaming cache well beyond the 32 MiB of Zen 3, or perhaps give Intel a different dynamic to its future processor portfolio.
As we move into more a chiplet enabled environment, some of those chiplets could be an extra cache layer. However, to put some of this into perspective.
- Intel's Broadwell's 128 MiB of eDRAM was built (is still built) on Intel's 22nm IO process and used 77 mm2 of die area.
- AMD's new RX 6000 GPUs use '128 MiB' of 7nm Infinity Cache SRAM. At an estimated 6.4 billion transistors, or 24% of the 26.8 billion transistors and ~510-530mm2 die, this cache requires a substantial amount of die area, even on 7nm.
This would suggest that in order for future products to integrate large amounts of cache or eDRAM, then layered solutions will need to be required. This will require large investment in design and packaging, especially thermal control.
Many thanks to Dylan522p for some minor updates on die size and pointing out that the same 22nm eDRAM chip is still in use today with Apple's 2020 base Macbook Pro 13.






