Original Link: https://www.anandtech.com/show/7334/a-look-at-alteras-opencl-sdk-for-fpgas
A Look at Altera's OpenCL SDK for FPGAs
by Rahul Garg on October 9, 2013 8:00 AM EST
Efficiency vs flexibility is one of the fundamental tradeoffs in any engineering discipline and it is true in computer architecture as well. For any given task, for example video decode, dedicated hardware is a more power-efficient solution than writing a software decoder that runs on a general purpose processor such as the CPU, or even a GPU's SIMD arrays. Chips designed for a specific purpose are called Application Specific ICs or ASICs. However, designing and manufacturing ASICs is obviously difficult and once a chip is deployed, you cannot use the dedicated silicon area to anything else.
FPGAs, or field programmable gate arrays, fall somewhere between general purpose processors such as CPUs and ASICs in the spectrum of programmability and efficiency. FPGAs consist of a large array of logic blocks and memory cells. The logic blocks are typically small programmable lookup tables that can be used to compute simple logic functions. The connections between the cells are also reconfigurable. Multiple programmable logic blocks and the connections can be configured to create more complex units such as ALUs.
You can utilize the reconfigurability of the FPGA to convert it into a computing device specialized for your application. For example, consider an algorithm that is only performing certain types of integer arithmetic. In this case, you can reconfigure the FPGA to act as a large set of integer ALUs with support for the integer operations needed by your application. There is no need to waste any logic cells on floating point logic, and further the integer ALU can be custom for your application instead of a generic unit. Thus, for some applications, an FPGA implementation can often offer much higher performance/watt than a CPU or a GPU implementation of the same algorithm. The efficiency of FPGAs comes partly from the fact that the hardware is reconfigured for your application.
In turn, the integer units in your FPGA will likely not be as efficient (power or area-wise) as an ASIC specifically designed and optimized for your application. However, unlike an ASIC, if you decide to tweak your algorithm in the future, you can simply reflash your FPGA with the new program rather than going to the drawing board again to design, validate and manufacture new ASICs while throwing out the old ones. Some FPGAs even allow for dynamic partial reconfiguration, where one part of the FPGA is reprogrammed while the other part is still active.
However, programming FPGAs has traditionally been difficult and requires expertise in specialized "hardware description languages" (HDLs) like VHDL or Verilog. Some other options, such as SystemC, have also remained somewhat niche. There has been considerable interest in easier tools for programming FPGAs and this is where OpenCL comes in. OpenCL is considerably easier to learn and use than tools like VHDL and Verilog thus addressing one of the traditional weakenesses of FPGAs. Further, there is already university courses and industrial workshops teaching heterogeneous programming concepts in OpenCL or similar languages like CUDA or C++ AMP and thus the number of programmers familiar with OpenCL concepts is increasing quite rapidly.
While experts will likely continue using HDLs, OpenCL will enable many more programmers to use FPGAs. Even HDL experts may use OpenCL as a quick way to prototype their ideas on an FPGA. Interestingly, Xilinx (the biggest FPGA vendor currently) has recently also announced that they are working to bring OpenCL for their FPGAs in the future but no timeline has been announced. In this article we are looking at Altera's OpenCL offering which is already available and shipping. I will add one caveat before proceeding further. My own expertise and experience is primarily in using OpenCL (and similar APIs) on GPUs and CPUs, and not in FPGA or HDLs. You can think of this article as CPU/GPU programmer's view of the FPGA world. I don't have first-hand experience with Altera's SDK yet. This article is based upon my reading of the Altera documentation and whitepapers as well as various FPGA related literature around the web. The folks from Altera were also a big help for this article, as they were able to get answers for many of my questions.
Altera's Products and Roadmap
Altera designs and manufactures FPGA chips and these chips are then sold to partners and clients. CPU and GPU companies typically have multiple products differing in specificatons such as number of cores, frequency, features, memory interfaces etc. Similarly, Altera offers multiple product lines and multiple products within each line. Products are differentiated along specifications such as the number of adaptive logic modules (ALMs), the type and size of on-chip memory and external I/O bandwidth. FPGA vendors have also started including some additional programmable processors on-chip. For example, some of Altera's Stratix V FPGAs integrate DSP blocks on chip and Cyclone V FPGAs integrate ARM CPU cores on-chip. FPGAs may also have high-speed transceivers on-chip to connect to external I/O devices such as video cameras, medical imaging devices, network devices and high-speed storage devices. Networking and high-speed streaming/filtering type applications are particularly suited for such devices.
A block diagram of Altera's Stratix V FPGA (source) showing the core logic fabric with logic blocks and interconnects, on-chip memory (m20k blocks), DSP blocks, transceivers and other I/O interfaces is shown below:
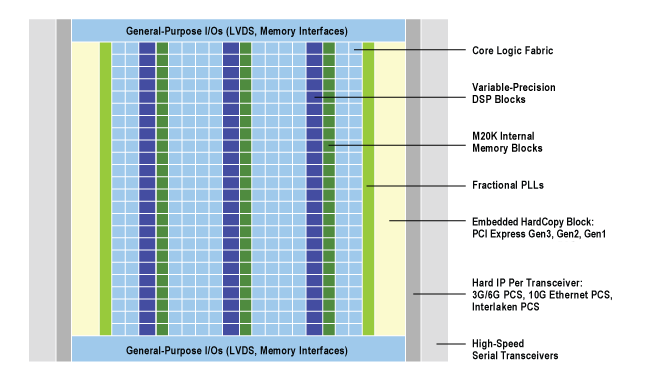
Altera partners will design a product, for example a PCIe based board, around the FPGA and may add their own customizations such as I/O interfaces supported on the board, peripherals as well as the size and bandwidth of associated onboard memory (if any). PCIe based boards are far from the only way to deploy FPGAs and some customers may choose a custom solution. However, we will focus on the PCIe based use case for this article.
Altera's current generation high-end product line is under the brand Stratix V and is currently their only product series to support OpenCL. Stratix V series is currently built on a 28nm process at TSMC. Interestingly, FPGA manufacturs are typically one of the first products to adopt new process technologies. Altera's 28nm products started shipping well before the first 28nm GPUs or mobile CPUs. Altera has also announced 20nm products (branded Arria 10). Significantly, Altera has announced a deal with Intel to fabricate their upcoming Stratix 10 branded 14nm FPGAs in Intel's manufacturing facilities.
Altera introduced a private beta for OpenCL on FPGAs late last year. The SDK has now been made public. Altera's implementation is built on top of OpenCL 1.0 but offers custom extensions to tap into the unique features of FPGAs. More information can be found on Altera's OpenCL page. They are also adopting some features, such as pipes, from the OpenCL 2.0 provisional spec. From a performance standpoint, Altera has posted whitepapers where they show that FPGAs offer much higher performance/watt on some applications compared to CPUs and GPUs. Typical FPGA board power used in Altera's studies is somewhere in the range of 20W which is much lower than the high-end discrete GPUs such as Tesla series GPUs which are often in the 200W range. Altera claims that OpenCL running on an FPGA will either outperform the GPU or match its performance at considerably lower power on some applications. Altera does not claim that this will be true for every application but I do think it is a reasonable claim for some types of applications.
We will go into some OpenCL terminology and how the concepts map to FPGAs. Next we will look at some details of Altera's OpenCL implementation and finally I will offer some concluding remarks.
OpenCL Programming Model and Suitability for FPGAs
OpenCL is an open-standard programming interface developed by the Khronos group designed particularly for parallel and heterogeneous computing. OpenCL can be used to program various types of hardware including CPUs, GPGPUs, FPGAs and many-core coprocessors like Xeon Phi or Adapteva's Epiphany. Each hardware vendor that wants its hardware to be exposed to OpenCL needs to provide an OpenCL driver for its hardware. For example, OpenCL drivers are available for various CPUs and GPUs for Windows, Linux and Mac and Altera is now providing OpenCL drivers and associated development tools for their FPGAs. Prior to OpenCL, there were no standard programming languages that exposed coprocessors on an equal footing. Thanks to the rise of GPGPU, the idea of accelerators and coprocessors has entered the mainstream and having a standard interface to accelerators is a big win for FPGA vendors. In many ways, the concepts that apply to programming a discrete GPGPU placed on a PCIe board also apply to FPGAs.
We go over some OpenCL terminology.
Host and devices: The CPU is called the host, and each hardware that has an OpenCL driver is called a device. Each device can have one or more compute units and each compute unit can have multiple processing element. This is shown visually below (figure from Hands on OpenCL course).
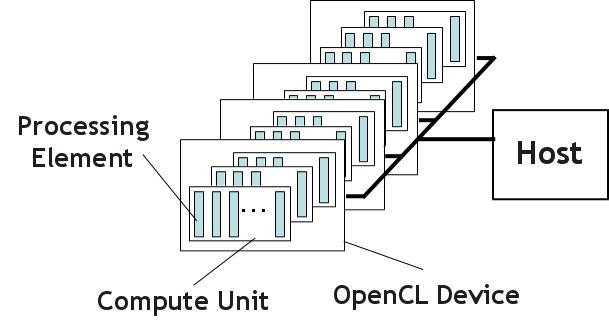
For example, Nvidia Titan GPU contains 15 SMX units and each SMX unit corresponds to a compute unit in OpenCL and each SMX has 192 processing elements. On FPGAs, the number and complexity of each compute unit is not fixed and instead is customized to your application.
Unlike say C, C++, Java or Python, OpenCL cannot be used standalone. Instead, the main program runs on the CPU (the host) as usual and typically only the computationally intensive parts of the program are written in OpenCL and called from the main program. However, work is not automatically distributed across various devices. Instead, the application program can query the OpenCL runtime for the list of all OpenCL compatible devices in a system and can choose the appropriate device for each computation.
Device memory: Each device has its own memory space where it can allocate arrays of data (called buffers) that can be read/written from OpenCL programs. In a discrete GPU or an FPGA, the buffer objects will typically reside in the RAM placed on the PCIe based board that contains the GPU or FPGA chip. For example, in a GPU such as Radeon 7970, the buffer objects will typically be placed in the GDDR5 RAM. OpenCL provides functions to copy data between host (CPU) memory and device memory. Some vendors also allow transferring data between multiple devices in a system directly without CPU intervention.
Kernels: OpenCL programs consist of kernels, which are similar to functions in C. Kernels can read/write from buffer objects that are passed as arguments to the kernel. Kernels are written in a C-like programming language. The OpenCL driver for a given hardware compiles it to the appropriate format. For CPUs and GPUs, the vendor's OpenCL driver will compile it to the native instruction set of the processor. We will get into how kernels are compiled by Altera's SDK in the next section.
Work-items, work-groups and parallelism: Unlike say C, where usually a function call leads to execution of a single instance of a function, the host launches the kernels across a 1D, 2D or 3D grid of "work-items". Each work-item can be thought of a conceptual thread and each work-item executes the same kernel function. However, each work-item knows its index in the thread and will typically compute different parts of a solution.
For example, let us say you wanted to add two vectors of length N. This is how you will do it in plain C:

You can write a kernel where each work-item adds one element of the vector corresponding to its index. Here is the sample OpenCL kernel.

In this case, each work-item is performing the work done by one loop iteration in the C code. Thus, if you wanted to add vectors of size 1000, you will launch this kernel with 1000 parallel work-items. OpenCL is an inherently parallel API and particularly suited for highly parallel problems.
Work-items are organized into work-groups, which are small grids of say 8x8 work-items, and items within a work-group can synchronize with each other but items from different work-groups cannot. This work-item and work-group organization maps particularly well to GPUs. FPGAs also prefer highly parallel workloads but the way they get compiled to FPGAs is very different and we will get to that soon.
Local memory: Accessing memory is an expensive operation. CPUs include hardware-managed caches with the hope that the data that is reused in the program can be brought into the cache once and then read/written multiple times from the cache. However, some architectures such as all recent desktop GPUs from AMD, Nvidia and Intel include small amount of fast memory on-chip that acts as a software managed cache. OpenCL provides a construct called "local memory" to expose such software managed caches. Each work-group can allocate local memory (typically upto 32 or 64kB per work-group) and all work-items in the work-group can read/write from the local memory. Local memory is implemented via the software managed cache on GPUs while CPUs allocate it in regular RAM and hope that it will be end up in the cache during program execution. FPGAs also include on-chip memory that can be used to implement OpenCL's local memory construct in hardware. Some members of the Stratix V series include upto 52Mbit (~6.5MB) of on-chip memory that can be used as local memory. In comparison, Radeon HD 7970 includes about 2MB of local memory on-chip and a GTX Titan includes about 450kB of local memory.
You can learn more about OpenCL at the official page at Khronos or look over some tutorials such as the recently released Hands on OpenCL. Overall, the OpenCL programming model looks to be a surprisingly good fit for FPGAs. Concepts such as host/device separation, device memory vs CPU memory, inherently parallel programming model and finally the local memory abstraction all look to be very well suited to FPGAs.
Altera's OpenCL Implementation Details
We go over how OpenCL kernels are compiled to FPGAs, and discuss some of the unique advantages of Altera's implementation over, say, GPUs.
Kernel compilation
Before getting into FPGAs, let us first look at how OpenCL kernels are compiled to GPUs. I am going to oversimplify things here so the discussion is not totally accurate, and details vary considerably across GPUs, but the objective is to give you a good idea of the concepts.
Every GPU has its own instruction set. Each vendor's OpenCL compiler compiles OpenCL to the native instruction set of the GPU being targeted. OpenCL work-groups typically get mapped to a compute unit in a GPU, and each compute unit can run many workgroups in parallel. Each compute unit has a fixed number of resources such as number of registers and local memory that get divided between the workgroups. Thus, the number of work-groups that can run in parallel depends upon the resources required to run one workgroup. Very approximately, arithmetic operations of work-items within a work-group get mapped to ALUs within a compute unit. If there are 64 ALUs in a particular compute unit, then arithmetic instructions from 64 work-items are processed at once by each compute unit.
Now let us look at Altera's OpenCL compiler. Altera's OpenCL compiler reconfigures the FPGA so that it becomes a custom processor designed for computing your kernel. For example, in our vector add example, each work-item does 2 loads (one from vector A, one from vector B), one floating-point add and one store (vector C). Then, Altera's compiler will generate 2 load units, 1 adder and 1 store unit.
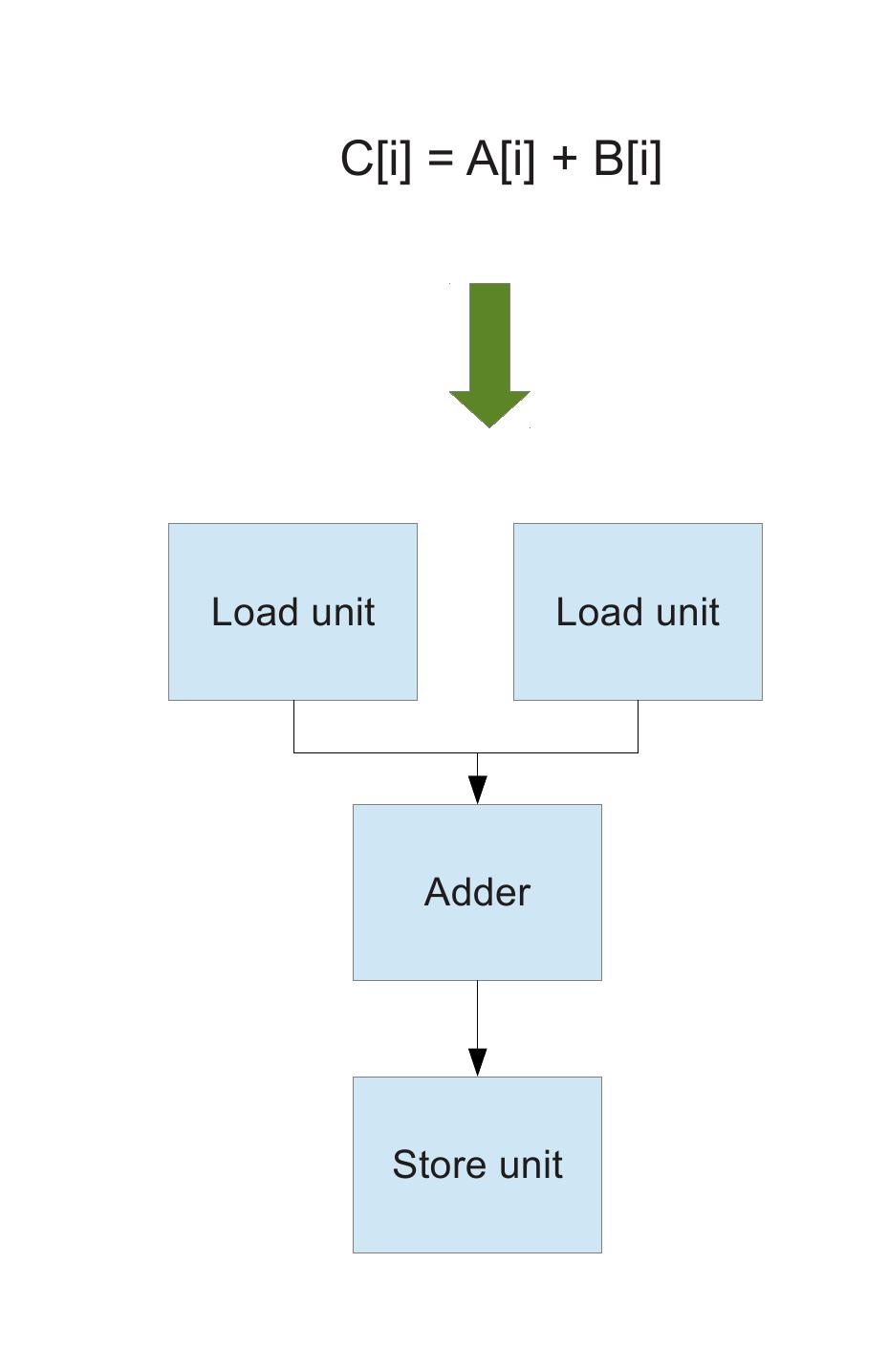
Behind the scenes, Altera's compiler is currently generating Verilog but this is an implementation detail that can change, and the programmer doesn't need to concern herself with it. As discussed earlier, Altera's OpenCL implementation tries to be smart and tries to avoid generating any unnecessary units. For example, if your kernel does not use floating point arithmetic, then no floating-point logic is generated. Further, let us say your kernel has operations such as (a*b*c + d*e). Such operations would map to multiple instructions in a CPU or a GPU but in an FPGA, the compiler may generate an ALU that performs this operation in a single step.
One potential weakness of FPGAs is that the compilation of OpenCL kernels to FPGAs can take time and so Altera primarily provides an offline compiler. Compiling OpenCL kernels for CPUs or GPUs typically happens in the order of hundreds of milliseconds to seconds on most modern machines. However, compilation time for FPGAs can be significantly longer and can often be in hours instead of seconds.
UPDATE: See comment from Kishonti (makers of tools like CLBenchmark, which we use ourselves for GPGPU testing) where they say that the compile time was indeed in hours for their tests. I can see that this can be an issue. On CPUs and GPUs, we are used to fast compile times which allows for quick iterations of testing and tuning kernels. On FPGAs, the development time can be longer due to compilation time bottleneck.
Mapping parallelism: Pipelining and resource replication
Another interesting aspect is how OpenCL's parallelism is mapped to an FPGA. In computer architecture, you can obtain parallelism in at least two ways: (a) Resource replication, obtained by replication of the same resource (such as a CPU core or a GPU compute unit) multiple times (b) pipeline parallelism, which relies on different types of functional units acting in parallel on different steps. For example, load/store units may act in parallel with ALUs.
Altera's SDK takes advantage of pipelining as well as resource replication. First we look into pipelining. Consider our vector addition example. It consists of 3 steps: load, add and store and Altera's SDK will generate a 3-stage pipeline. At any given time, upto 3 different work-items will be active in the pipeline in parallel. When work-item N is executing the store stage, work-item N+1 is executing the add stage, and work-item N+2 is executing the load. We show an example below:

Our example consists of a very simple problem and upto 3 work-items were executing in parallel in the pipeline. For more complex kernels, Altera's SDK will generate much deeper pipelines with many more work-items active in the pipeline at the same time. In a general purpose processor, the number of various functional units, such as ALUs and load/store units, as well as the functionality of each unit and the connection structure between these units is fixed at design time of the processor. This fixed structure may not be optimal for all applications. However, in an FPGA the pipeline structure and the number and types of functional units present is customized to suit your application.
If the pipeline generated for your application is simple and does not eat all the resources on the FPGA, then you can instruct Altera's SDK to also attempt to create multiple copies of the pipeline. However, instead of outright replication of the pipeline, in many cases a better option is to merge multiple work-items and effectively vectorize a problem. For example, in our kernel, we can modify the kernel so that each work-item computes a vector of 8 elements. Vectorization is somewhat more efficient but not always applicable. Altera's SDK allows you to control whether you want to vectorize or replicate your pipeline.
To summarize, Altera's SDK places pipeline parallelism at the forefront and can generate deep, application-specific pipelines. Resource replication is controlled by the programmer and depending on the problem can be done either by implementing a wider pipeline through vectorization or through outright pipeline replication.
Local memory
Next, we look at local memory. On GPUs, local memory is typically implemented using on-chip SRAM. On GPUs, this SRAM has a fixed size and a fixed number of banks, with each bank typically returning 1 or 2 results every clock cycle. For example, some GPUs provide 32kB of local memory per SMX and this is divided into 32 banks. Thus, on a GPU, the number of read/write ports to/from the on-chip SRAM is fixed. However, on an FPGA, the size and configuration of the local memory can be customized. One kernel may require a "deeper" local memory with fewer read/write ports, while another kernel may require a wider local memory with larger number of read/write ports. Thus, in addition to customized units and a custom pipeline, on an FPGA the local memory is also customized to your kernel. As mentioned in the previous section, compared to current GPUs FPGAs have relatively large amount of memory that can be used as local memory.
High speed I/O to external devices
One of the bottlenecks in many high performance applications is that the data to be processed comes from an external I/O device. For example, input data might be a large file read from an SSD, or streaming data from a video camera, or data from network port. Traditionally this data was transferred to a buffer in system RAM by the external I/O device, and then copied by the CPU to another temporary buffer in system RAM and finally copied to the accelerator/co-processor over PCIe. Obviously, this multiple copying of data is wasteful and can be a big bottleneck.
FPGAs can communicate to external world (PCIe, network connections, storage devices etc.) through transceivers. Different FPGA products have different number of transceivers with different datarates. Currently, the most impressive offering from Altera is the Stratix V GX with upto 66 14.1 Gbps (bidirectional) transceivers. The number of transceivers actually exposed by a given FPGA board depends upon both the FPGA used as well as the board design. Connecting an external I/O device may require additional logic and Altera and partners will readily sell you solutions for a number of standard interfaces. The high bandwidth I/O makes the FPGA ideal for streaming/filtering type applications.
Unfortunately, the OpenCL standard does not really cover this type of scenario well and so Altera is working on providing custom extensions to OpenCL that allow you to use external I/O devices as inputs or outputs of OpenCL kernels for streaming applications. Altera tells me this is similar to the pipes functionality introduced in the provisional OpenCL 2.0 spec.
It is worth mentioning that Nvidia provides a competing solution called GPUDirect for CUDA. As of CUDA 5.0, it is possible for external I/O devices such as other Nvidia GPUs, SSDs and network cards to read/write the GPU memory directly over PCIe bus without going through the host. However, the net bandwidth is limited to PCIe 3.0 x16 currently, which works out to about 16 GB/s in each direction which is much lower than the peak theoretically obtainable on, say, the Stratix V GX FPGA (~116 GB/s in each direction). In practice, Nvidia's GPUDirect solution is sufficient for many applications but there are definitely some applications where the FPGA's bandwidth advantage will be extremely important. Another limitation of Nvidia's GPUDirect is that it is currently only available in CUDA and not in OpenCL.
Conclusions: Altera's Offerings and Competitive Landscape
FPGA vendors have long preached about the efficiency of reconfigurable hardware over general purpose processors. However, FPGAs have often been rejected as an option by many due to the programming challenges associated with them. CPUs, and even GPUs, typically offered a much faster time to market and a larger talent pool of programmers. With OpenCL, FPGA vendors can play on an equal footing as far as programming is concerned. Earlier, the decision to use an FPGA over another accelerator required significant resource commitment. OpenCL allows FPGAs to be used as just another option lowering the risk and is potentially a game changer.
On a personal note, I am hoping for cheaper OpenCL capable FPGAs to hit the market. Currently, OpenCL capable FPGAs run into thousands of dollars. This is likely not an issue for the enterprise market typically targeted by FPGA vendors. However, OpenCL on FPGAs has not attracted as much mindshare as GPUs. GPU vendors have a huge advantage that anyone with a cheap laptop can start experimenting with and learning about GPUs. The easy and cheap access to GPUs enabled GPU computing to take off. Whenever computing technology has become cheaper and/or easier to program, it has enabled many creative products around it in fields not thought of by the original technology makers. FPGAs have not yet reached that stage. While there is a community of FPGA enthusiasts, enabling OpenCL on cheaper FPGAs can increase this community many-fold.
Altera's OpenCL offering effectively promises customized hardware for your OpenCL kernels and the claim is that FPGAs will be more efficient than CPUs or GPUs at many tasks. Applications that are not necessarily floating-point heavy, for example applications relying on custom integer datatypes, heavy bit-manipulation or fixed point calculations, are an area where FPGAs can shine because CPU and GPU hardware is not really tailored for such applications. The high-speed I/O connections available on an FPGA with external bandwidth far outstripping other accelerators is another advantage. I think streaming/filtering type of applications are an obvious niche that FPGAs can fulfill. On the other hand, accelerators such as Nvidia Tesla and Xeon Phi will likely continue to do well in many double-precision floating-point applications because these accelerators are heavily optimized for such use cases. Applications such as image processing or data visualization that can make use of dedicated graphics related hardware on GPUs are also best done on a GPU.
Finally, I would say I am cautiously optimistic at the prospect of using OpenCL on FPGAs. I am impressed by the theoretical potential for OpenCL on FPGAs. However, I would like to see third party studies comparing OpenCL SDKs for FPGAs and general purpose processors on various tasks to get a better understanding of performance and power consumption of various accelerator options. If you are evaluating GPUs or Xeon Phi for your application, you should definitely also consider evaluating OpenCL on FPGAs and compare their performance against other options for your application. OpenCL on FPGAs looks to be gaining steam and this will be an interesting space to watch in the near future and may very well be a turning point for wider adoption of FPGAs in various high-performance application segments.






