Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
The Results that Matter
Before you jump ahead to the charts below, we suggest taking some time to properly interpret the results. First of all, we simulate between 5 to 15 "busy" users on the web server per second. As a user clicks somewhere on the website, this can result in a few requests or tens of requests. For example, accessing the forum on the website results in two simple "GET" requests, while posting a reply results in an avalanche of 56 POSTs and GETs. That is why we report performance in "responses per second". Responses are somewhat similar from the CPU load point of view if you look at a statistically large enough number of them. User actions are so wildly different that in some cases performing two user actions per seconds can require more processing power and network bandwidth than 20 user actions per second.
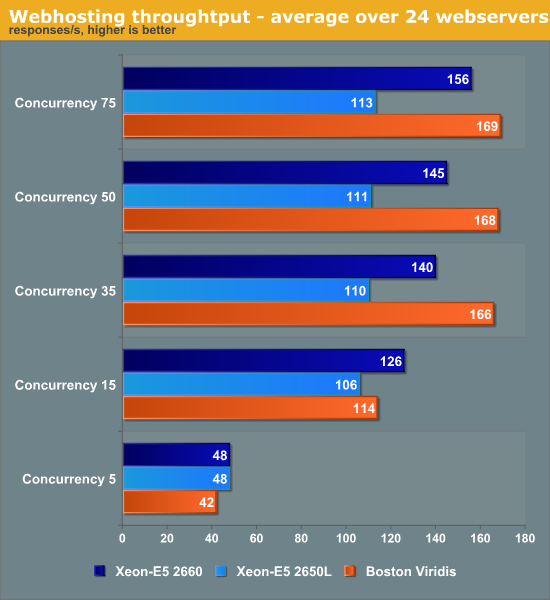
At the low concurrencies, the Intel machine leverages turboboost and its exceptionally high per core performance. At the higher web loads, the total throughput of the 96 (24x quad-core SoCs) ARM Cortex-A9 cores is up to 50% higher than the low power 32 thread/16 core (2x Octal core) Xeons. Even the mighty 2660 cannot beat the herd of ARM SoCs.
While we have lots and lots of experience with x86 servers, we had almost none with ARM based servers, so we met up with the people of Calxeda engineering and got some valuable optimization tips. It turns out that the internal switch fabric can be tuned in various ways. For example, the link speed from one node is by default set to 2.5 gbit/s, which is rather high considering that we are mostly CPU limited and use less than 0.5Gbit/s per node. Setting the link speed of each node to 1Gbit/s should lower power and gives more than enough bandwidth. We also updated to a slightly newer kernel (155) from the Calxeda kernel PPA (Personal Package Archive). This allowed us to make use of Dynamic Voltage and Frequency Scaling (DVFS, P-states) using the CPUfreq tool. First let's see if all these power saving tweaks have reduced the total throughput.
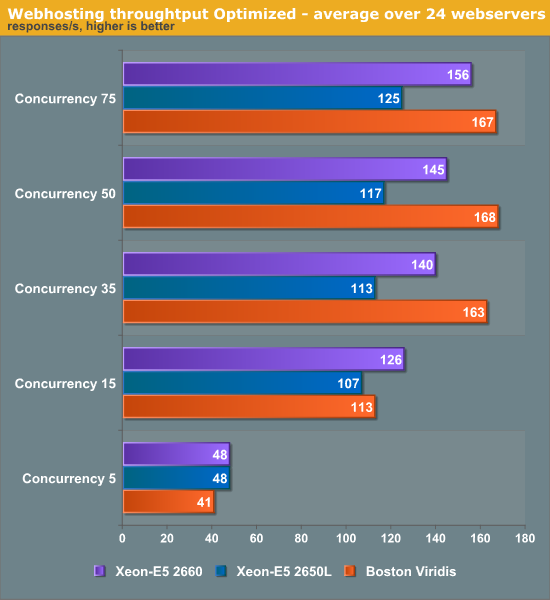
The changes did not give any boost in throughput (in many cases the scores might even be slightly slower), but the changes might lower power use and/or response times. Let's look at that next.
Response Times
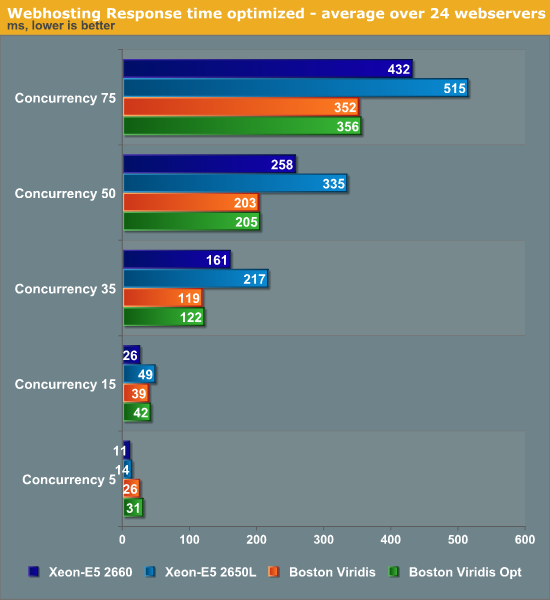
Again, the Intel machine performs better at lower concurrencies, but our ARM server delivers lower response times at high load. Our optimizations have had no effect on response times.








99 Comments
View All Comments
tuxRoller - Tuesday, March 12, 2013 - link
Why WOULD you expect DVFS to boost performance?You seem to think it slightly revelational that the scores are slightly lower (but perhaps statistically meaningless).
dig23 - Tuesday, March 12, 2013 - link
On-demand seems fair choice to me, its what best you can do on this OSes. But I will be very interested to see energy efficiency numbers when DVFS working on swarm of ARM nodes...:)tuxRoller - Tuesday, March 12, 2013 - link
It's not cpu governor I'm talking about but DVFS in particular.There's bound to be some small amount of latency involved with the process.
It's point isn't for best performance but energy efficiency thus why I made the comment in the first place.
JarredWalton - Tuesday, March 12, 2013 - link
There's the potential for DVFS to optimize for better performance on a few cores while putting some of the other cores into a lower P-state, but I think that would be more for stuff like Turbo Boost/Turbo Core. It's also possible Johan is referring to the potential for the optimizations to simply improve performance in general.CodyHall - Friday, March 15, 2013 - link
Love my job, since I've been bringing in $5600… I sit at home, music playing while I work in front of my new iMac that I got now that I'm making it online.(Click Home information)http://goo.gl/9u8us
JohanAnandtech - Wednesday, March 13, 2013 - link
Can you tell me where I got you confused? Because I write "This allowed us to make use of Dynamic Voltage and Frequency Scaling (DVFS, P-states) using the CPUfreq tool. First let's see if all these power saving tweaks have reduced the total throughput."So it should been clear that we are looking for a better performance/watt ratio. The interesting thing to note is that ARM benefits from p-states, and that Intel's excellent implementation of C-states makes p-states almost useless.
Twonky - Wednesday, March 13, 2013 - link
For information about a year ago the following post on the Linkedin ARM Based Group gave a link to a M.Sc. thesis publishing figures on the performance/watt ratio for Cortex-A8 and Cortex-A9 based boards:www.linkedin.com/groups/Single-CortexA8-CortexA9-in-comparison-85447.S.84348310
AncientWisdom - Tuesday, March 12, 2013 - link
Very interesting read, thanks!staiaoman - Tuesday, March 12, 2013 - link
Damn, Johan. As always- an incredible writeup. Interesting thought experiment to figure that an upper bound on damage to INTC server share might be found by simply looking at how much of the market is running applications like your web server here (where single-threaded performance isn't as important).Intel powering phones and ARM chips in servers...the end is nigh.
JohanAnandtech - Thursday, March 14, 2013 - link
Thanks Staiaoman :-). I'll leave the though experiment to you :-)